Knowledge Base Schedule
The Knowledge Base Schedule allows authors to schedule crawling, extraction, and training actions at a data source level to occur automatically.
Set up a schedule from the Knowledge Base page
- Go to the Knowledge Base and click the Schedules tab. The Schedules page displays all schedules set up for the different unstructured data sources.
- Click the New Schedule button. The New Schedule modal appears.
- Choose the desired unstructured data source.
- Select Next. The schedule configuration appears.
- Toggle on the actions to schedule. The following actions are available for scheduling: Crawl, Extract, and Train.
- Crawl, Extract, and Train
- Crawl and Extract
- Extract and Train
- Each action individually (Crawl / Extract / Train)
- Select the Start date.
- By default, the No end date toggle is turned on, which means the scheduler runs indefinitely. If you want the scheduler to stop on a specific date, turn off the No end date toggle, and then select the desired End date.
- Configure the occurrence, frequency, and interval.
- Click Save to save the schedule.
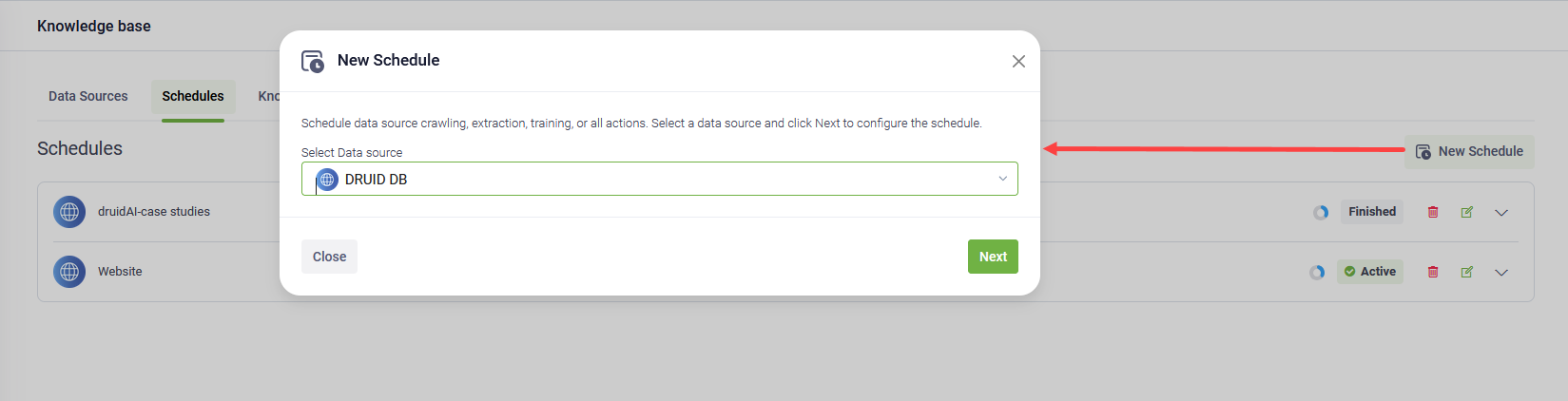
By default, the schedule is disabled. Select the toggle next to the data source name to enable it.
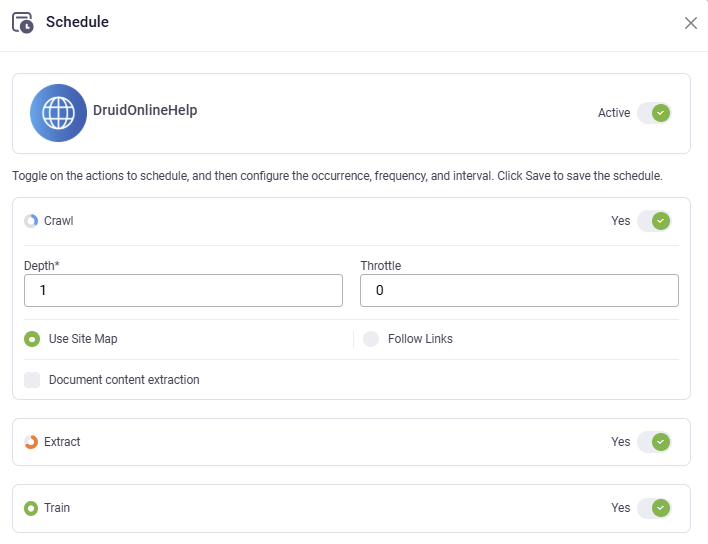
When you toggle on Crawl and Extract, additional action-specific parameters become available.
You can toggle on the following action combinations:
The selected actions will be performed on the data source based on the schedule.
Set up a schedule from the Data Source
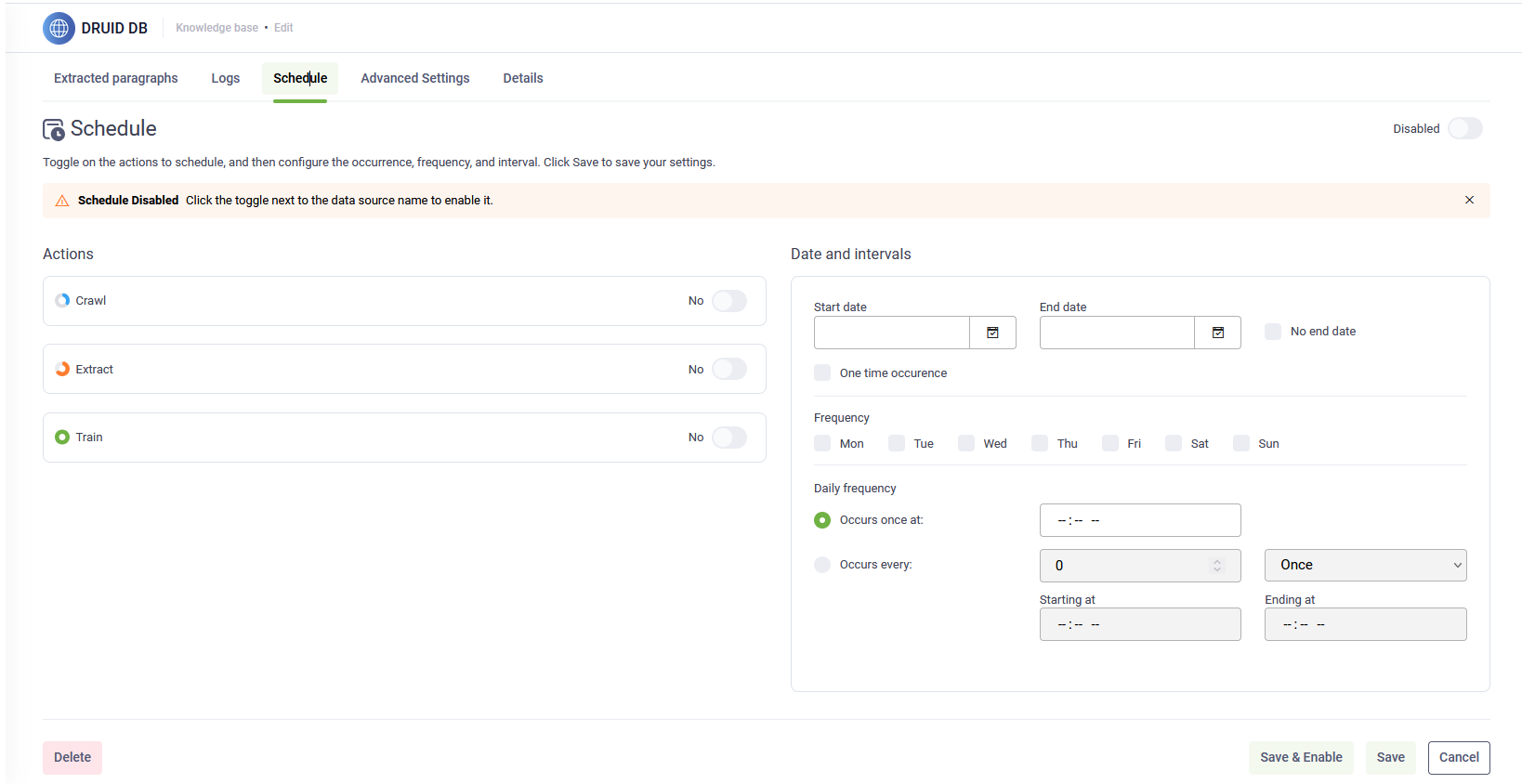
- Go to your data source and click the Schedule tab. The Schedule configuration page appears.
- By default, the schedule is disabled. Select the toggle next to the data source name to enable it.
- Toggle on the actions to schedule. The following actions are available for scheduling: Crawl, Extract, and Train.
- Crawl, Extract, and Train
- Crawl and Extract
- Extract and Train
- Each action individually (Crawl / Extract / Train)
- Select the Start date.
- By default, the No end date toggle is turned on, which means the scheduler runs indefinitely. If you want the scheduler to stop on a specific date, turn off the No end date toggle, and then select the desired End date.
- Configure the occurrence, frequency, and interval.
- Click Save to save the schedule.
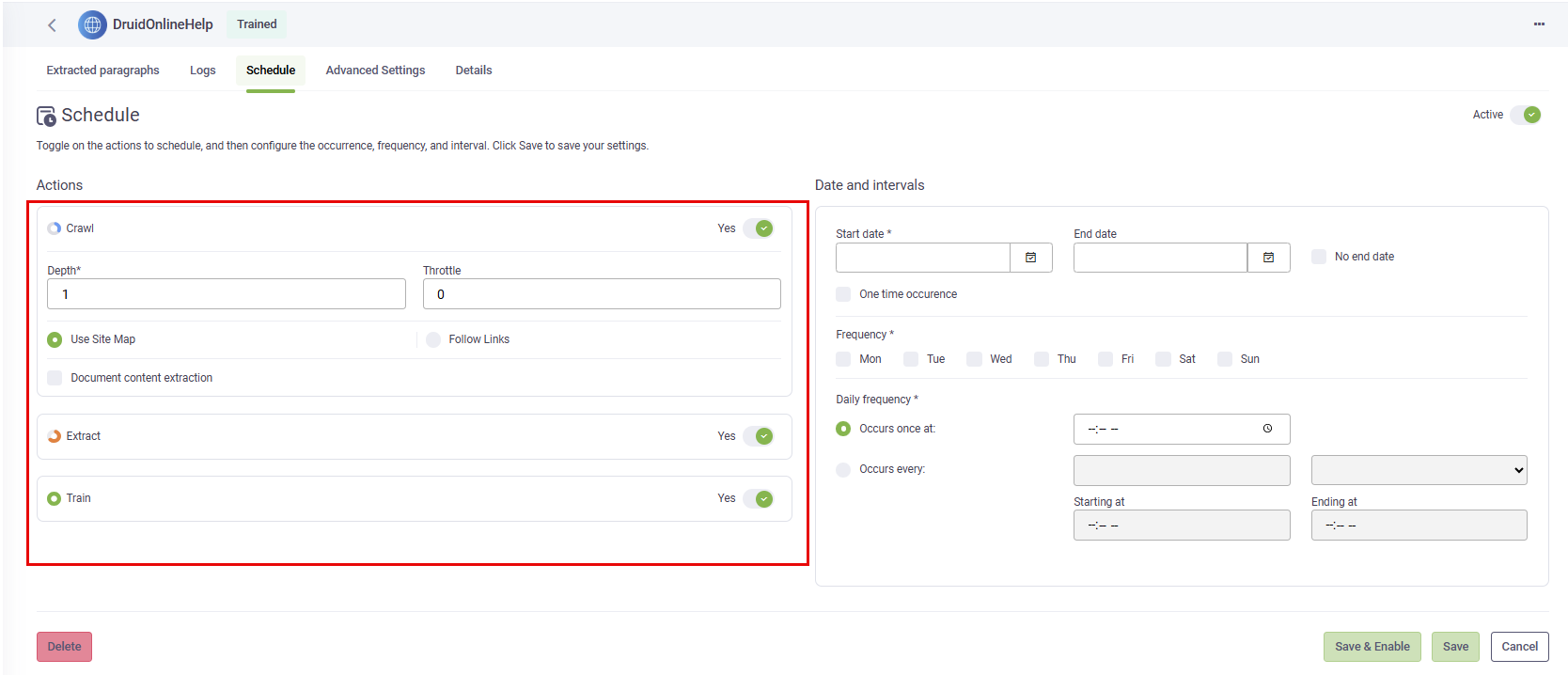
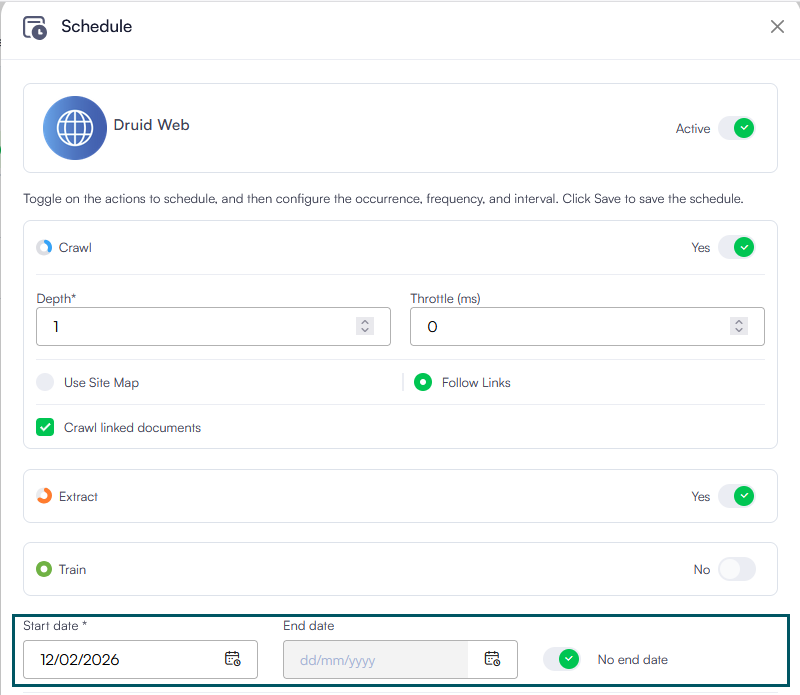
When you toggle on Crawl and Extract, additional action-specific parameters become available.
You can toggle on the following action combinations:
The selected actions will be performed on the data source based on the schedule.
Rules for performing scheduled actions
Each action will notify the next action set that can start. If all slots for an action are in use (for example, two crawls are running in parallel), the next one will wait in a queue and will start when one of the first two finishes. The same applies to extraction. If more than one training action is set to start in the same interval, they will accumulate.
Schedule Statuses
A schedule can have one of the following statuses:
- Disabled: The schedule has been set up but has not been enabled.
- Active: The schedule has been set up and has been enabled.
- Finished: The schedule occurrence has been reached.
Update, disable or delete a schedule
Because you can set only one schedule per data source, if you need to set up a different schedule, go to the schedule configuration page and modify it based on your needs.
You can delete a schedule if you want. However, if you want to keep the configuration but stop automatically performing the actions, we recommend disabling it instead. This ensures that you can easily adjust the schedule and enable it in the future.