Google Drive Data Sources
A Google Drive data source enables you to securely and efficiently integrate documents stored in your Google Workspace into your Knowledge Base (KB). By incorporating Google Drive data sources, you can ensure your AI Agent responses are accurate and comprehensive, utilizing internal files, policies, or FAQs located on your cloud storage.
This feature allows you to extract paragraphs from Excel, Word, and PDF files stored in your specified Google Drive folders.
Adding a Google Drive data source
This section will guide you through the process of adding a shared drive data source.
Prerequisites
- You have a Google Cloud account.
To create data sources from Google Drive storage, follow these steps:
Step 1: Create the data source
Creating the data sources, requires a Google Cloud setup and data source setup in the Druid Portal.
Set up Google Cloud project and service account
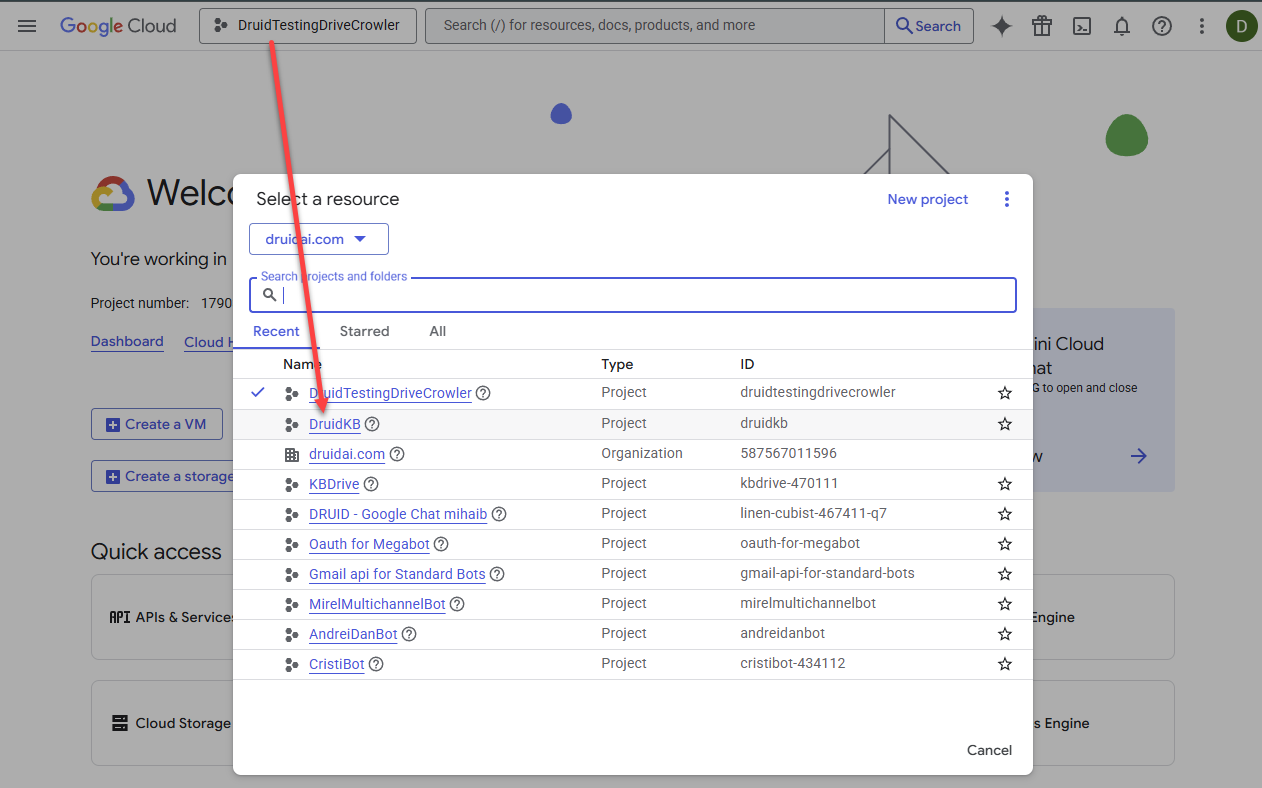
- Log into the Google Cloud Console.
- Click on the project picker.
- In the 'Select a resource' pop-up, click New project.
- Enter a name for your project.
- Click Create.
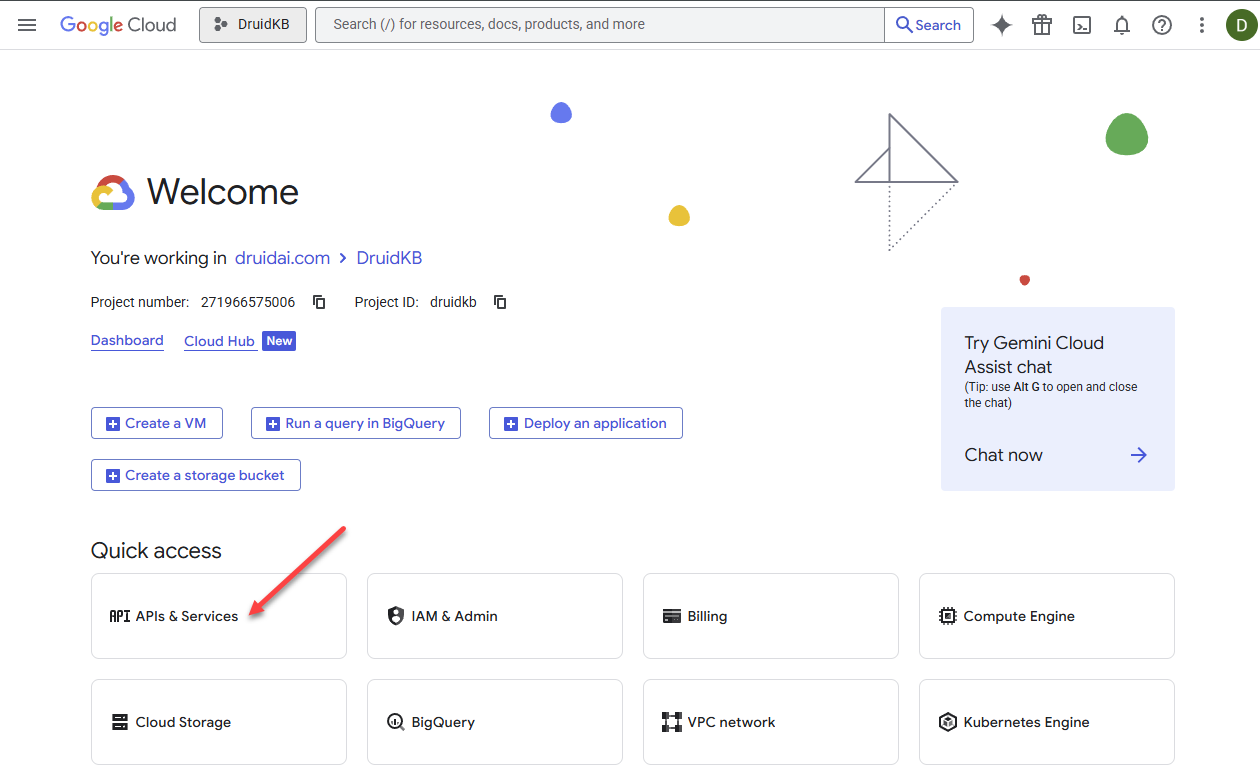
- Select the new project from the project picker.
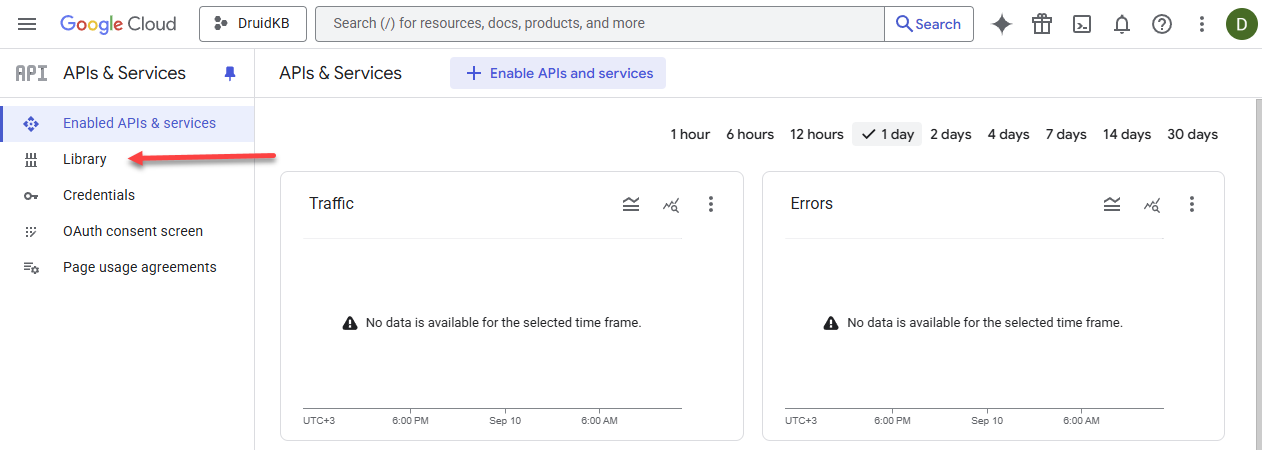
- In the Quick access area, click on APIs & Services.
- Go to Library.
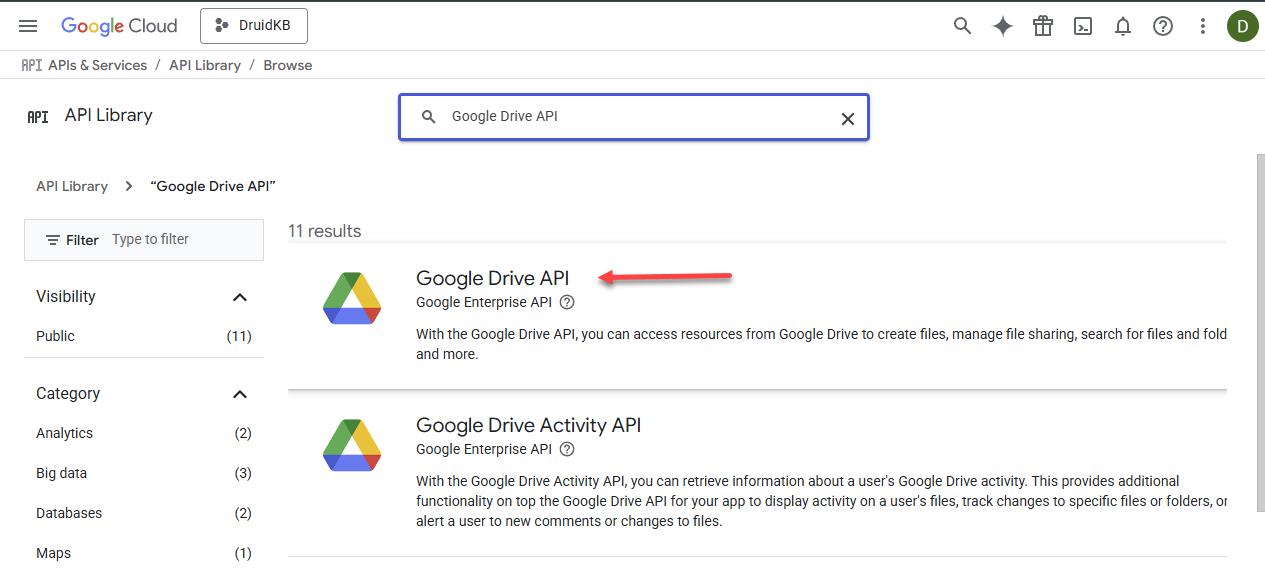
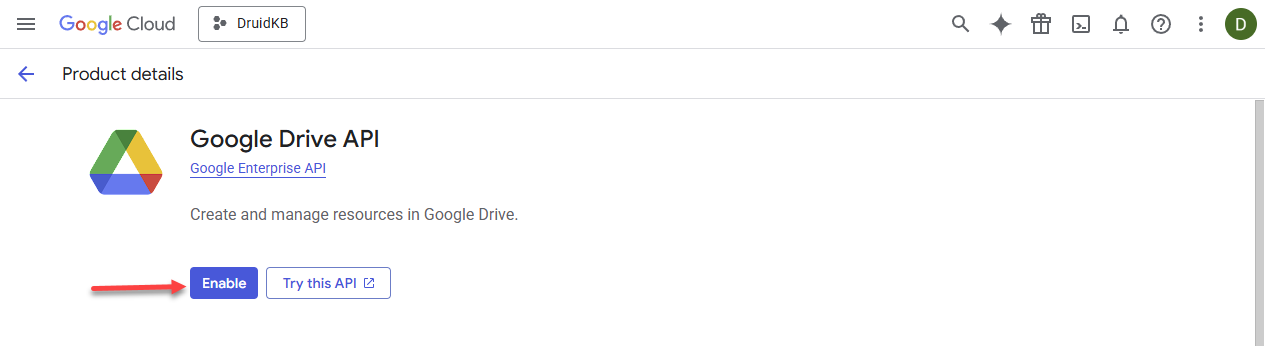
- Search for Google Drive API or scroll down until you find it, then select it.
- Click Enable.
- Wait until the Google Drive API is enabled.
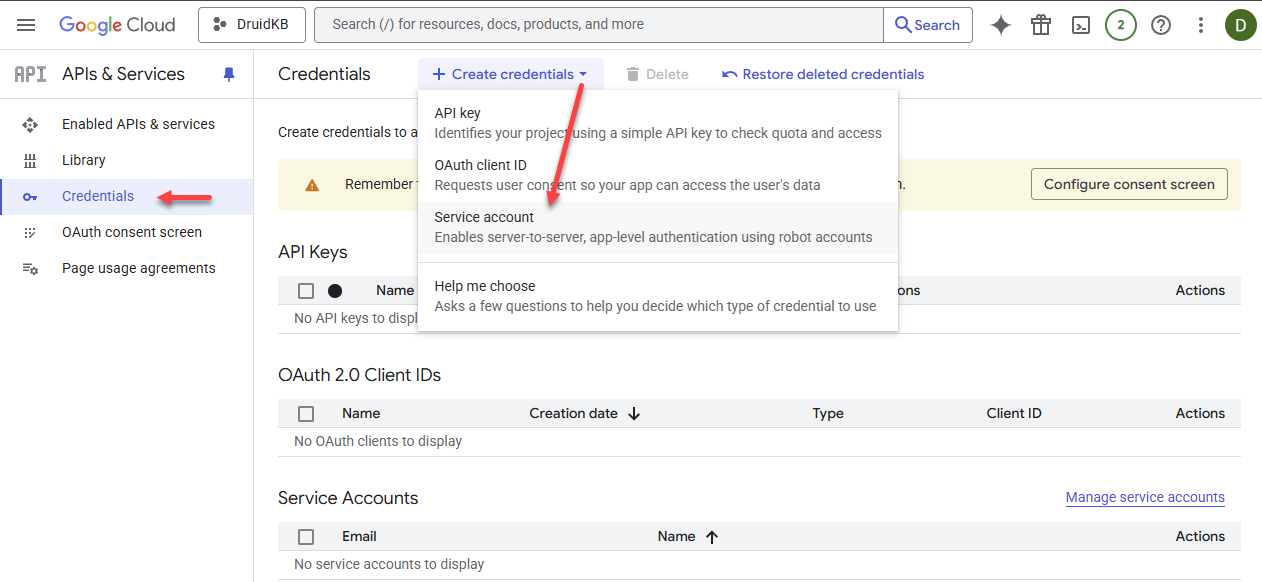
- Click Create credentials on the menu.
- From the Create credentials drop-down, select Service account.
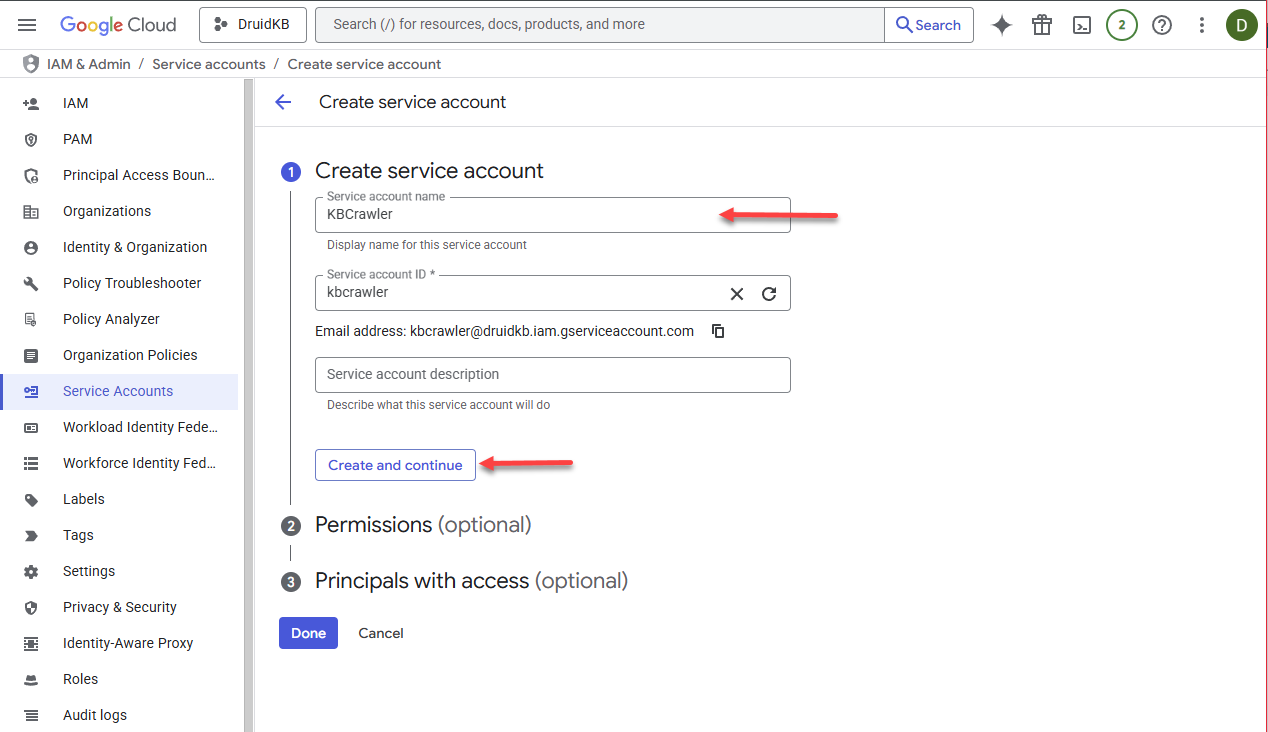
- Enter Service Account name and click Create and continue.
- Select the Viewer role.
- Click Done.
If you’re using a personal Google Cloud account instead of a business account, the New Project page looks slightly different.
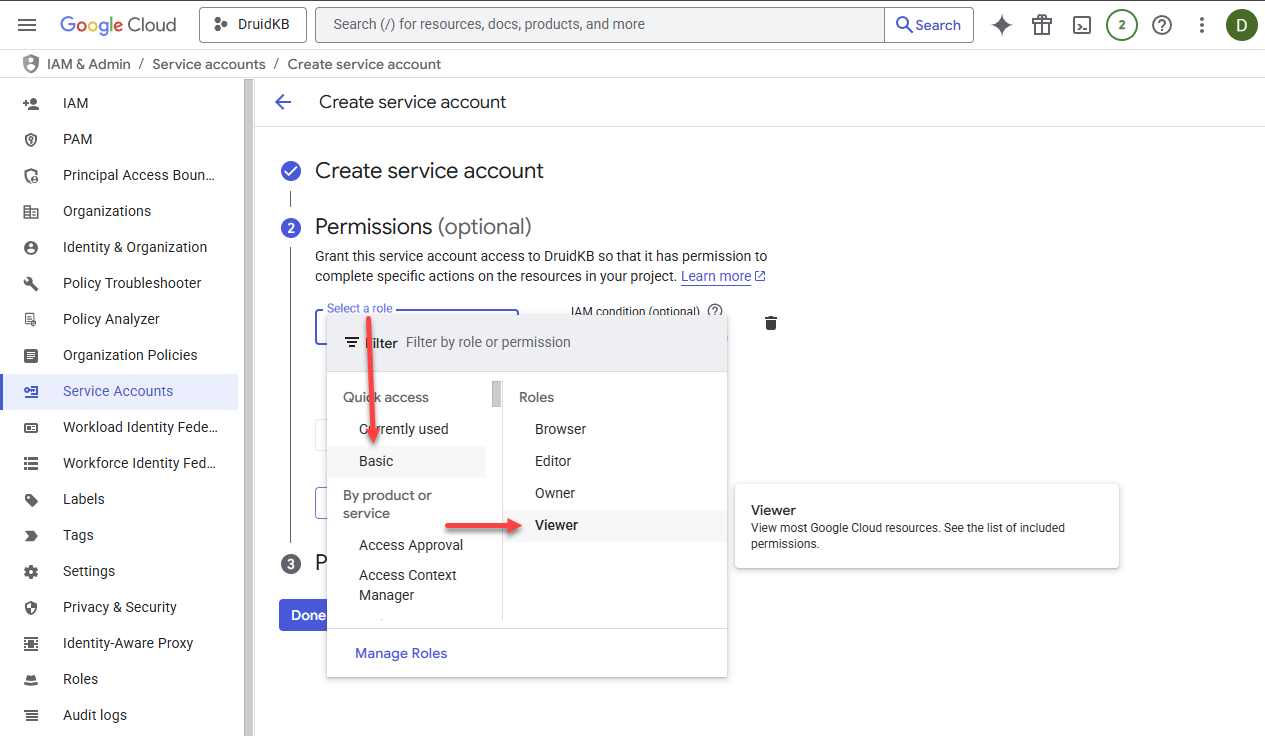
You can add additional roles if needed.
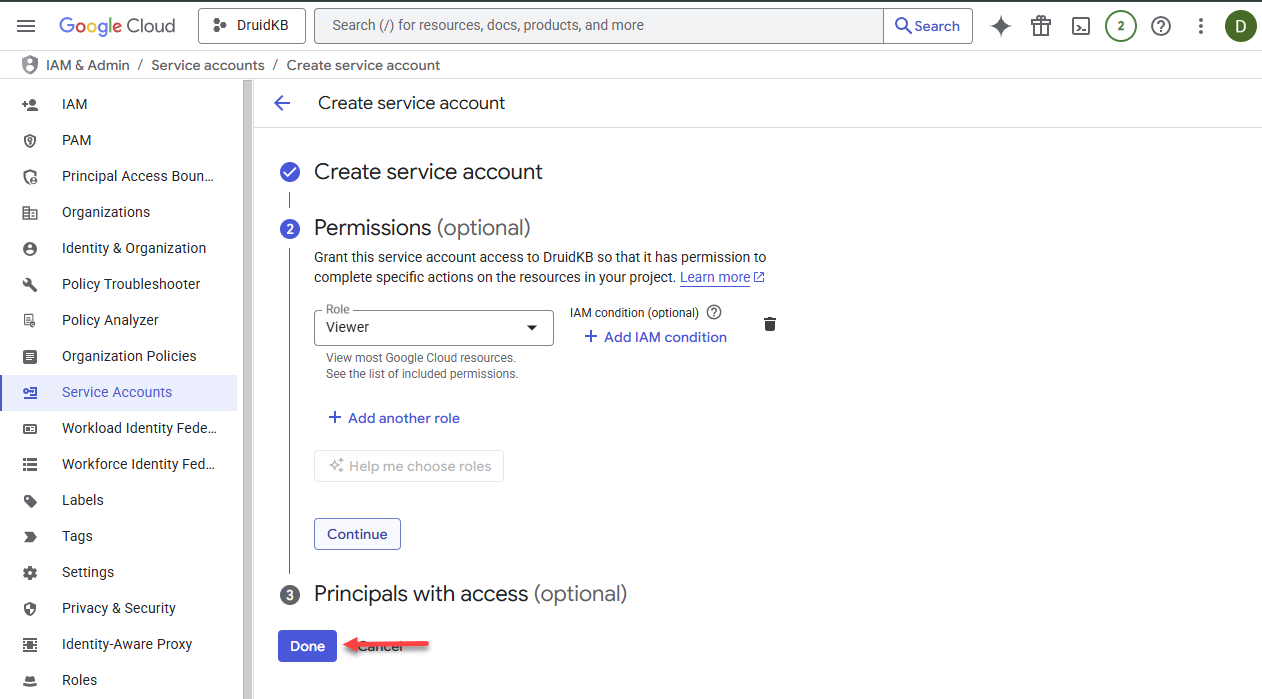
The service account is created.
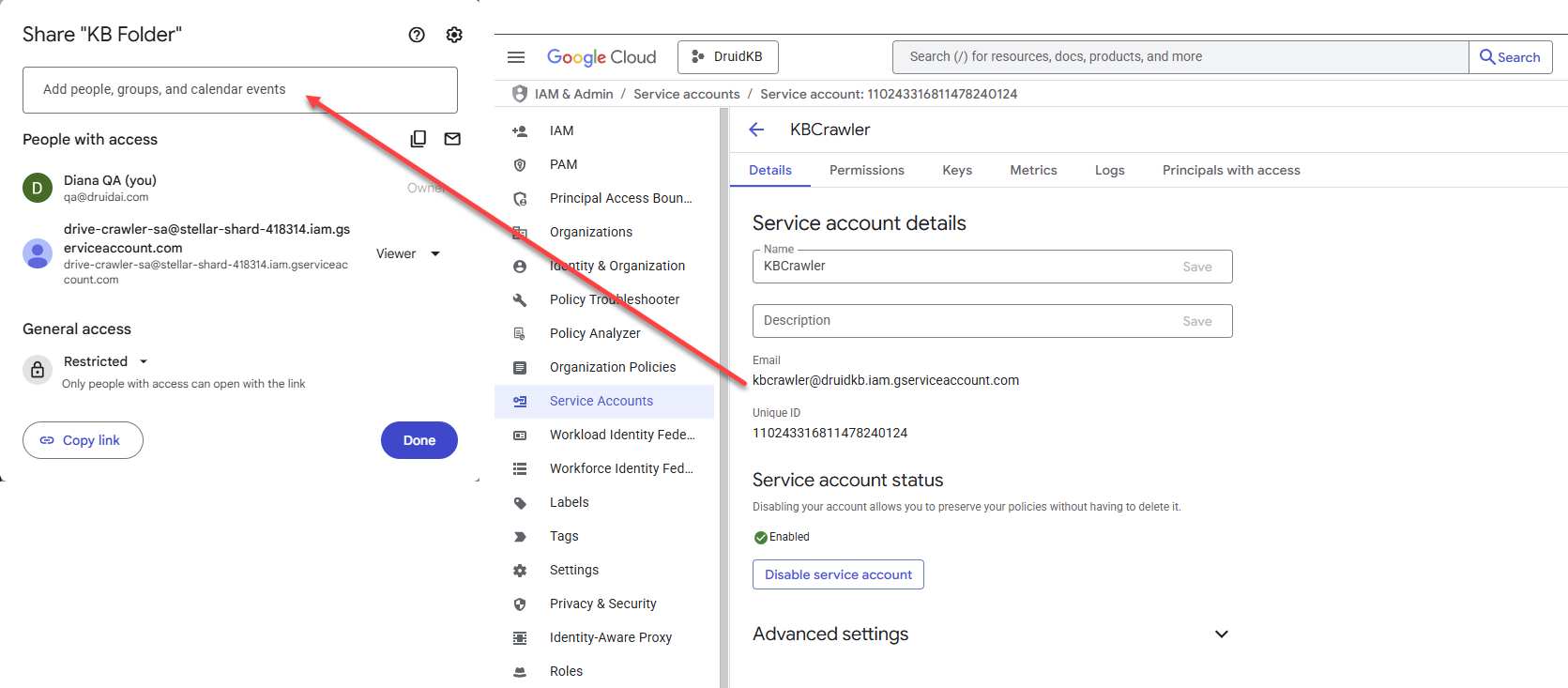
Generate a private key
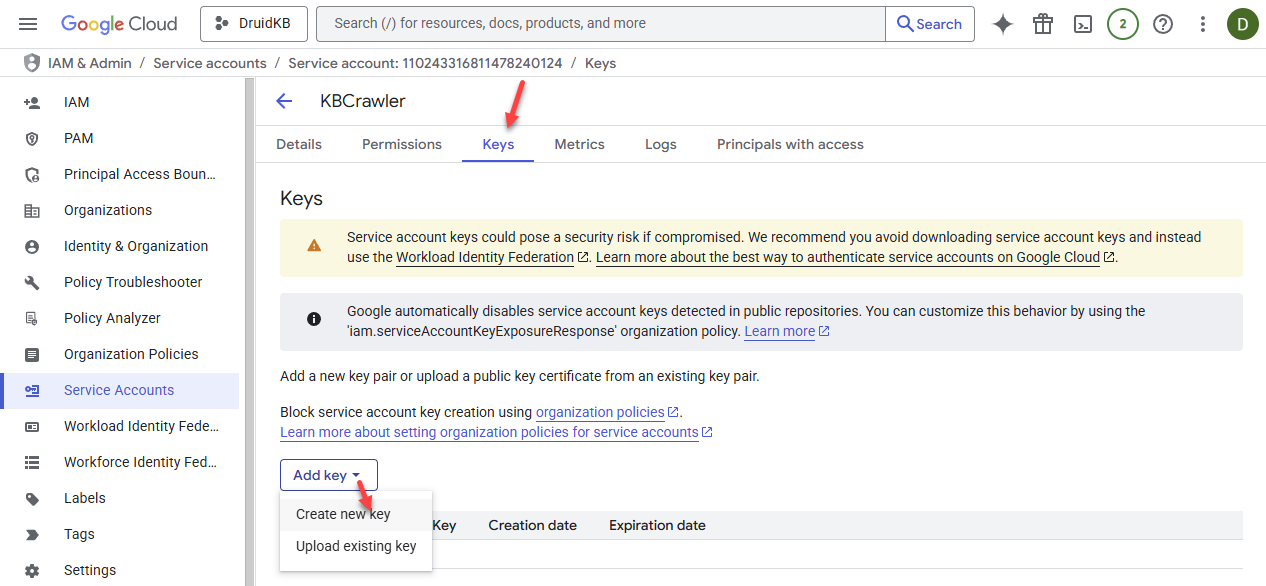
- Click on the service account you created.
- Click on the Keys tab.
- From the Add key drop-down, select Create new key.
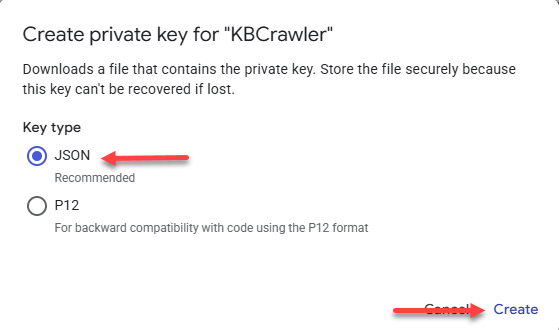
- Leave JSON selected and click Create.
- The private key file is automatically downloaded to your computer (default Downloads folder).
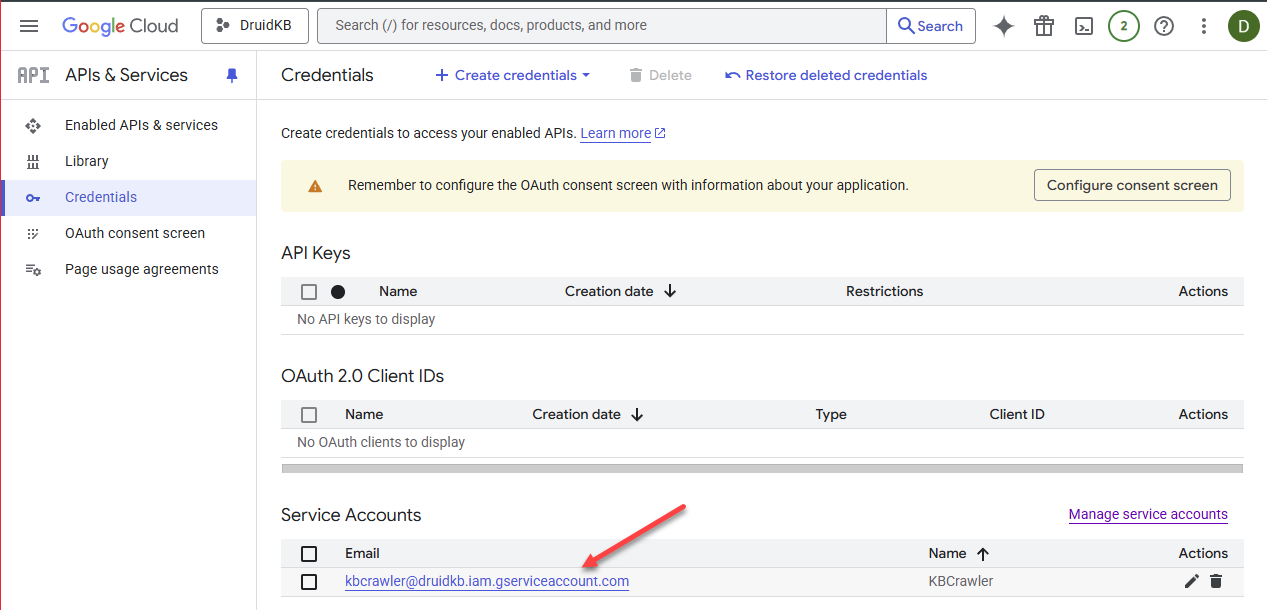
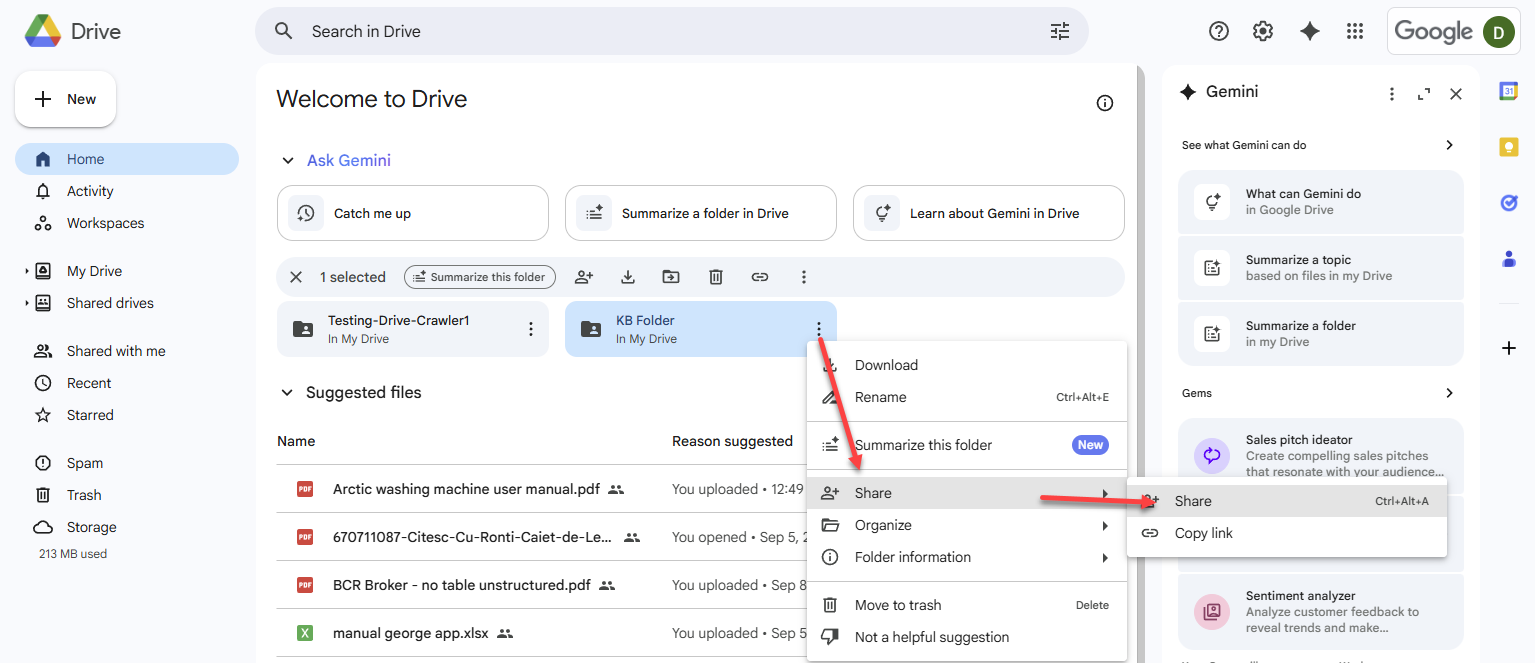
Share the Google Drive folders you want to crawl
- Open Google Drive.
- Locate the folder you want to crawl and click Share.
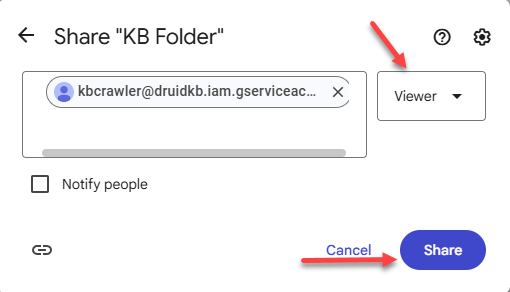
- In the Add people and groups field, enter the service account email address you created in Step 1.
- From the permissions list, select Viewer and click Share.
- If prompted, confirm that you agree to share the folder with an external email address.
Once the Google Cloud setup is complete, you can create the data source in Druid.
Create the Google Drive data source in Druid
To create a Google Drive data source, follow these steps:
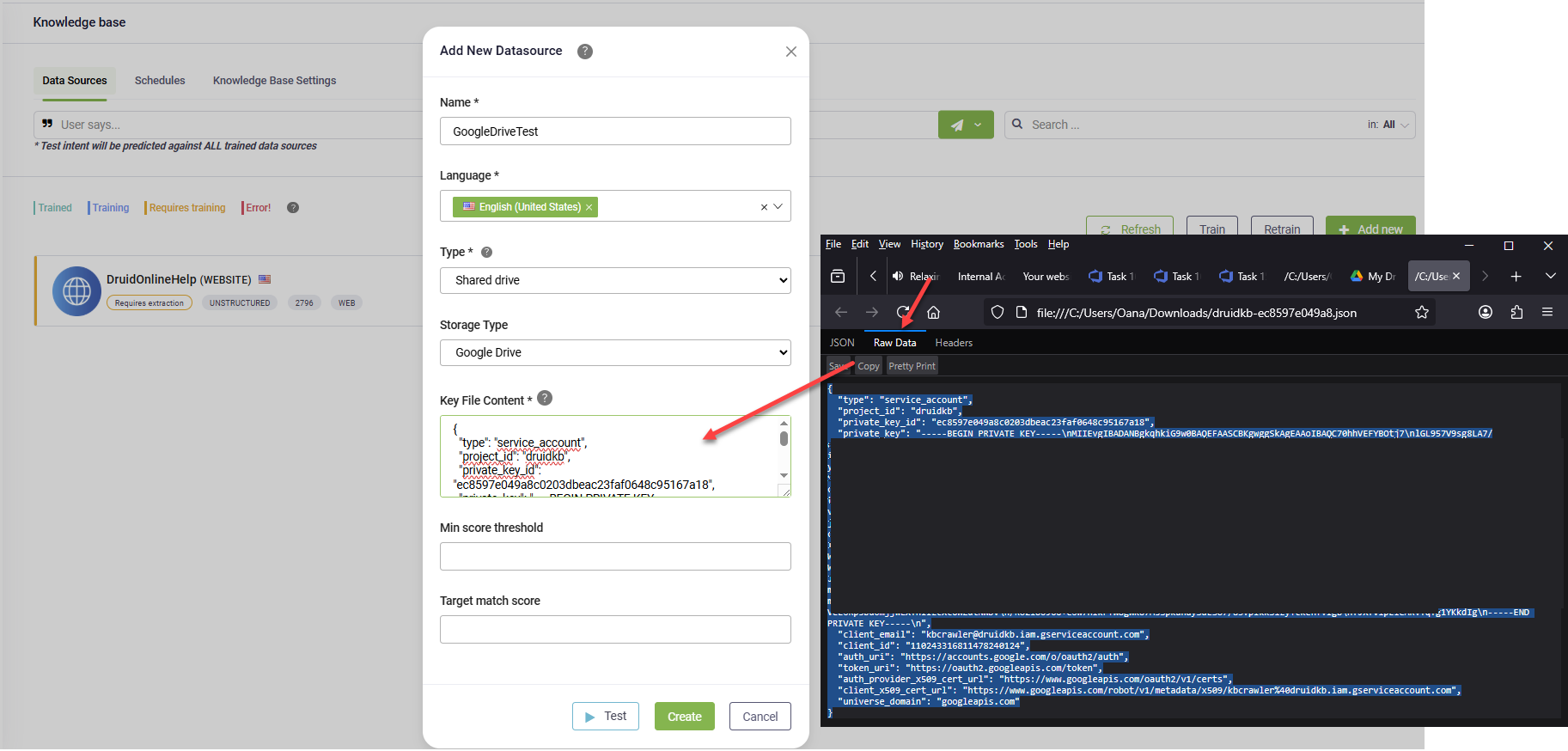
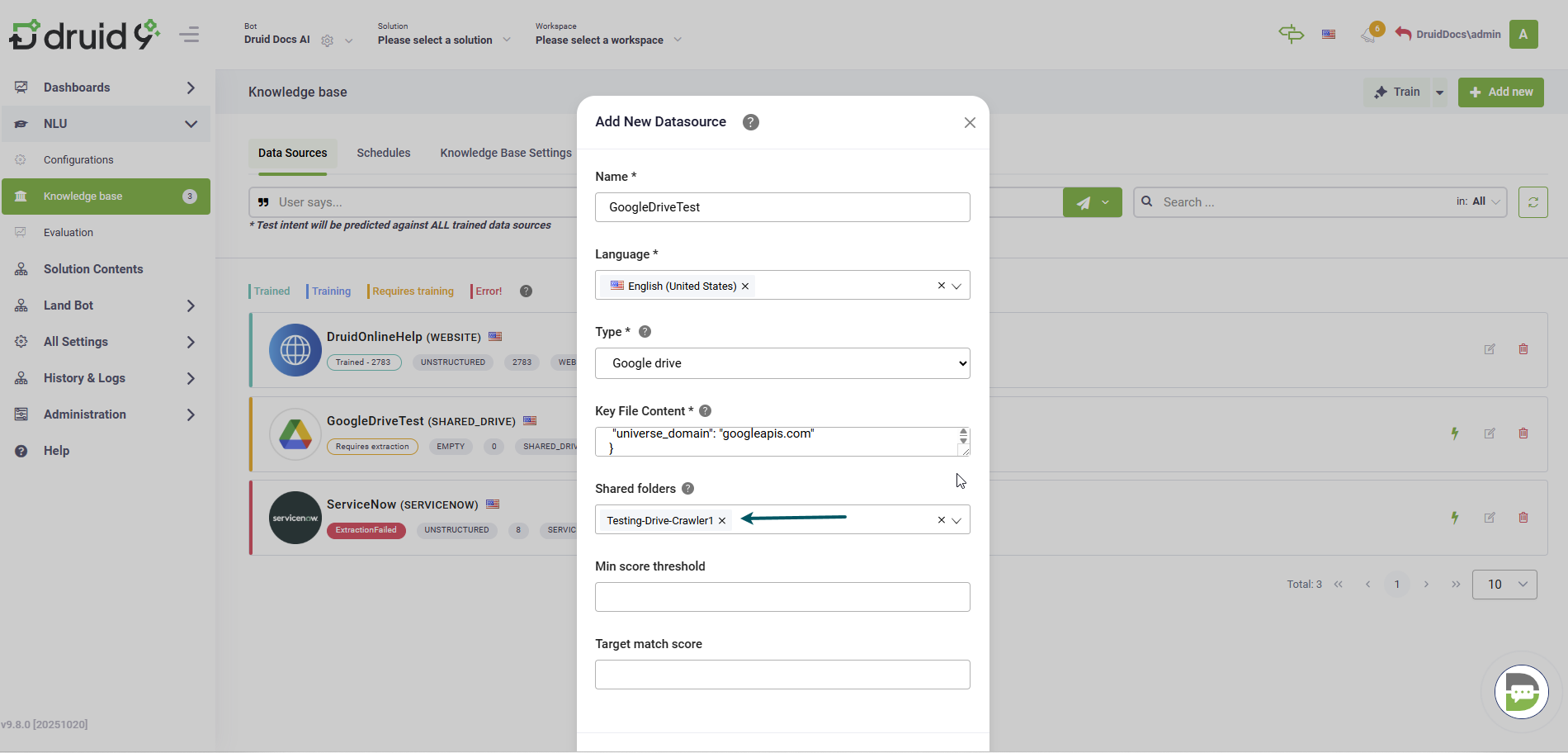
- Click the Add New button. The Add New Data Source page opens.
- In the Name field, provide a name for the data source. This helps you identify and search for the data source easily.
- From the Language drop-down, select the language of the data you upload. It must be one of the AI Agent languages.
- From the Type drop-down, select Google drive.
-
In the Key File Content field, paste the entire content of the private key file you downloaded in Step 2. Open the file in a text editor, copy all of its raw JSON content (including the opening and closing braces), and paste it here.
- From the Shared folders drop-down, select the root shared Google Drive folder or specific subfolder(s) to include in the Knowledge Base.
- To verify the Key File Content, click the Test button. If the check fails, check you have properly entered the content of the private key file. You can also test it later by going to the Details tab of the data source and clicking the Test button at the bottom of the page.
- Click Create. The new data source opens and you can start crawling.
Step 2. Crawl the data source
On the Knowledge base page click the edit icon to edit the data source. The data source configuration page appears by default on the Extracted Paragraphs tab. Upon reaching the configuration page, you'll notice that the content of the root reflects the file structure from the Uri link you provided during data source creation. By default, all folders and files are excluded from scraping. To include files / folders for scrapping, click the three dots displayed at the right-side of the item and click Include.
Click the Start crawling button. The Start Crawling Parameters page appears.
Define the crawling policy by setting the parameters described in the table below.
| Parameter | Description |
|---|---|
| Depth |
The number of directory levels the crawler will explore from the URL. NOTE: To improve crawling efficiency, crawl each node individually instead of the entire root, especially if the storage has a deep structure. Set the depth to '0' to achieve this.
|
After you define the crawling policy, click Start.
By default all nodes are excluded from scrapping. To crawl specific nodes, click the dots next to the desired node in the file repository explorer and select Crawl Path.
When the crawling completes, the extracted articles display under the Extracted Paragraphs tab.
Step 3. Train the data source
To ensure the KB Engine searches through the data source paragraphs, train your data source by clicking the Train button at the top-left corner of the data source or select Train data source from the actions menu. Alternatively, you can Train all data sources.
Testing the data source performance
Testing the performance of a data source is important because it ensures that the extracted paragraphs are relevant. This process helps identify and rectify any issues, improving the overall quality and effectiveness of your AI Agent responses. By validating the data source performance, you can enhance user satisfaction.
To test the performance of the data source, on the Extracted Paragraphs page, in the User Says area, enter a question and select the language. All matched paragraphs will be displayed along with their scores.
You can improve the performance of the data source by reviewing and editing the paragraphs based on your needs.
Editing paragraphs
To ensure your Knowledge base high quality, we recommend you to review the extracted paragraphs and take the proper actions to improve them: open the URL from where the crawler extracted the paragraph and compare the content, edit or delete the paragraph. Refine your paragraphs by transforming unstructured data into a question-and-answer format.
To edit a paragraph, click the Action icon displayed inline with the paragraph and click Edit. Edit the paragraph Title and / or Content and save the changes.
Fine-tuning Predictions
You can configure Advanced Settings at both the data source and node/leaf levels to achieve more precise predictions. This approach offers granular control, allowing you to adjust the extractors and trainable elements, resulting in better accuracy and performance. Unlike KB-level settings, which apply changes broadly, this targeted method adapts configurations to the unique needs of each data source or element, streamlining your authoring process.
Fine-tuning at the data source level
- Navigate to the desired data source.
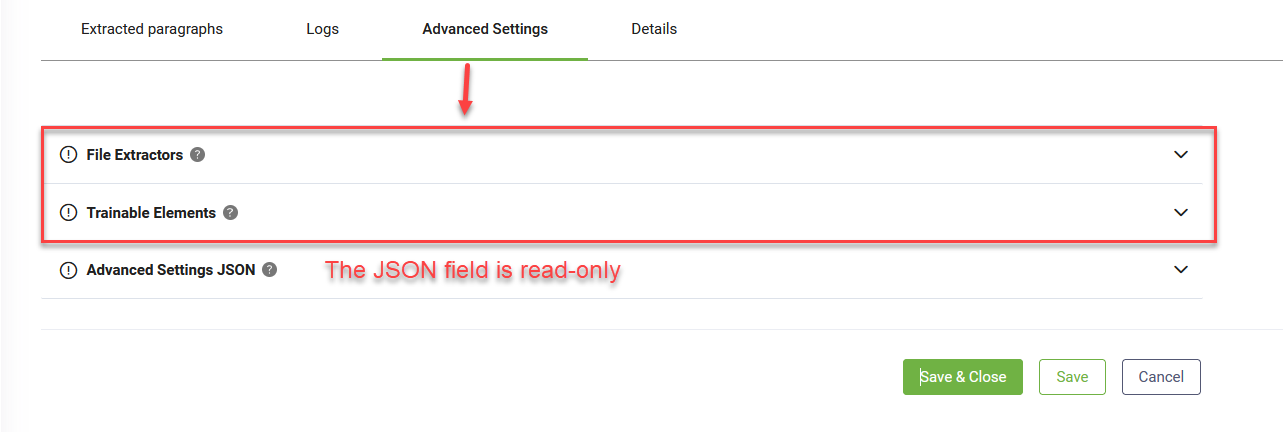
- Select the Advanced Settings tab.
- Modify advanced parameters as needed and save the settings.
Fine-tuning at the node or leaf level
- In the tree explorer, select the desired node or leaf.
- On the right side, select the Advanced Settings tab.
- Modify advanced parameters as needed and save the settings.
Reset advanced settings
To reset advanced configurations at the data source and node/leaf levels to match the KB Advanced settings, go to Knowledge Base > Advanced Settings and click the Save to All button. This action streamlines your settings management by applying consistent KB Advanced settings across your entire configuration with just one click.
Enhance KB prediction
Refine your articles by transforming unstructured data into a question-and-answer format. Edit articles and add question / title / short description.
Access the Knowledge Base Advanced Settings, set the "trainableColumns" parameter to "Question,Answer", then train the Knowledge Base. The KB Engine will leverage both questions and answers from unstructured data sources during the prediction process, ultimately leading to improved prediction accuracy.