File Repository Data Sources
A File Repository data source empowers you to extract data from both structured (Word and Excel) and unstructured (Word, PDF, and Excel) files. The File Repository feature has reached its final version in DRUID 7.4, offering enhanced functionality and usability for managing your File Repository data sources:
- Maximize Capabilities: Utilize the full potential of a File Repository data source.
- Efficient File Management: Upload multiple files to the same data source and organize them into folders for streamlined management.
- Enhanced Control: Take full control over data source extraction and maintenance processes.
- Seamless Maintenance: Easily maintain both the file repository structure and its content.
Adding File repository data sources
To add File repository data sources, follow these steps:
Step 1. Create the data source
- Click the Add New button. The Add New Data Source page opens.
- In the Name field, provide a name for the data source for easy identification and search.
- From the Language drop-down,select the language of the data being uploaded (must be one of the AI Agent languages).
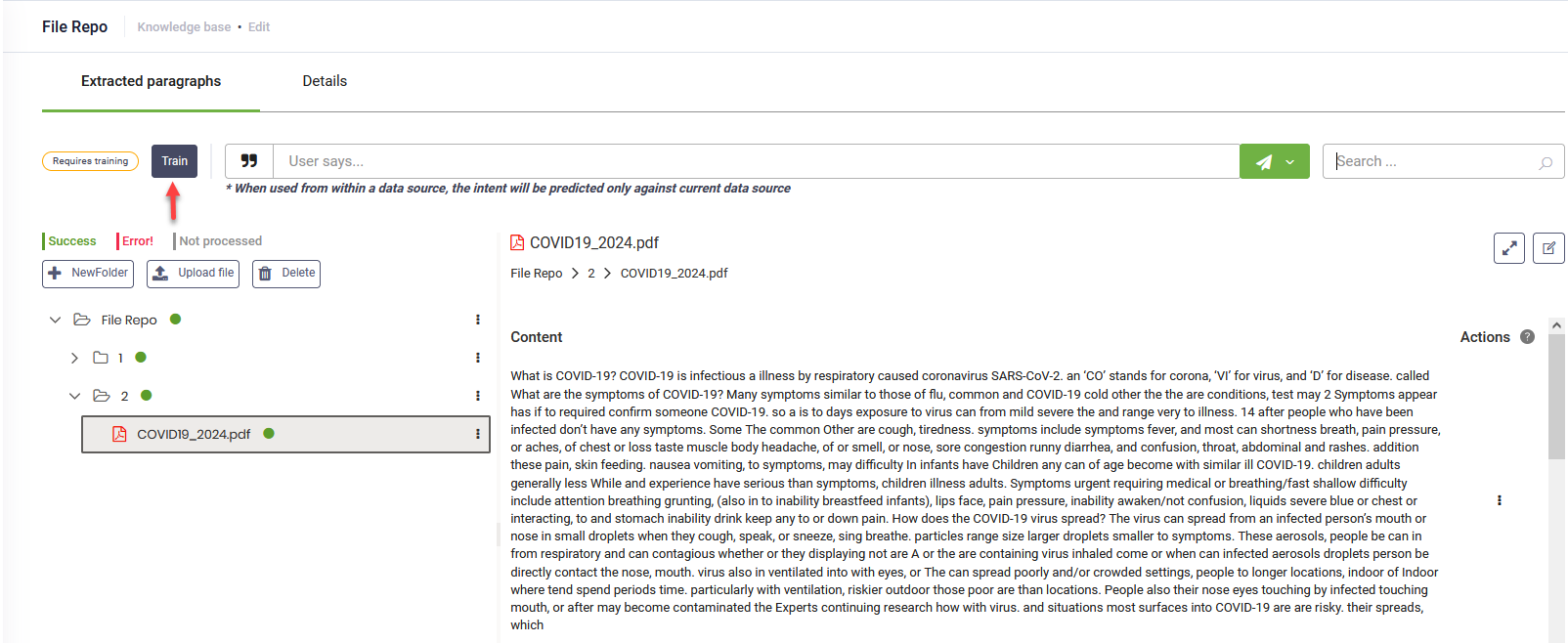
- From the Type drop-down, select File repository.
- Optionally, set the Min score threshold and the Target match score for the data source. If not set, the thresholds from the Knowledge Base will apply.
- Click the Create button.
Step 2. Define the structure of the file repository
The content of the File Repository is organized under the root folder, named after your data source. To add multiple files and organize them into specific folders, add folders first, then upload files into the desired folders.
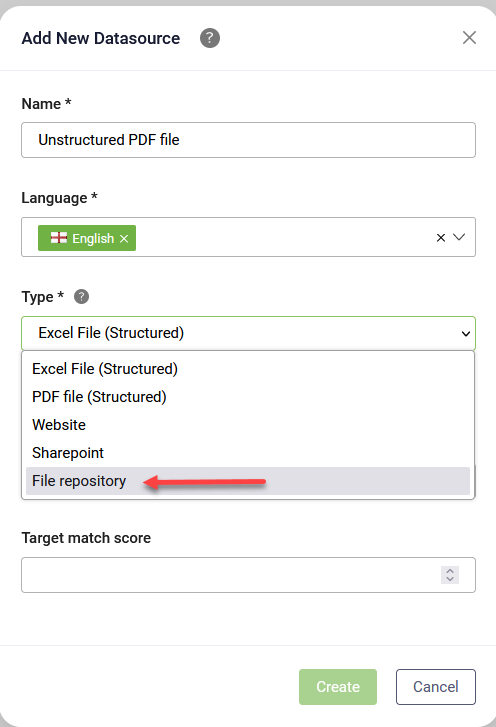
To add a folder, select the tree element under which the folder will be added and click the New Folder button under the data source status. Alternatively, hover over the tree element, click the dots next to it and select New Folder. In the pop-up, enter the desired folder name and click Save.
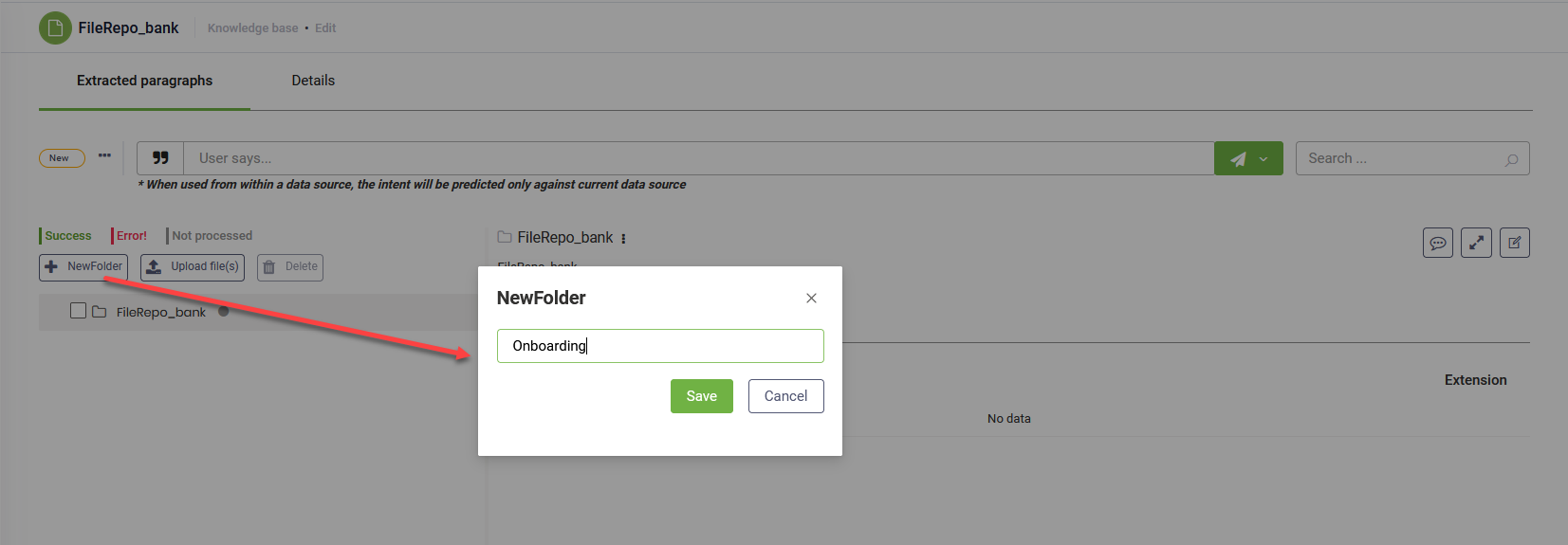
To upload a file, click on the node where you want to upload it, browse for the desired file(s), select it / them, and then click Open. You can upload multiple files at the same time.
In Druid 9.11 and higher, you can also upload video files as long as the file size is limited to 20 MB.
Add file
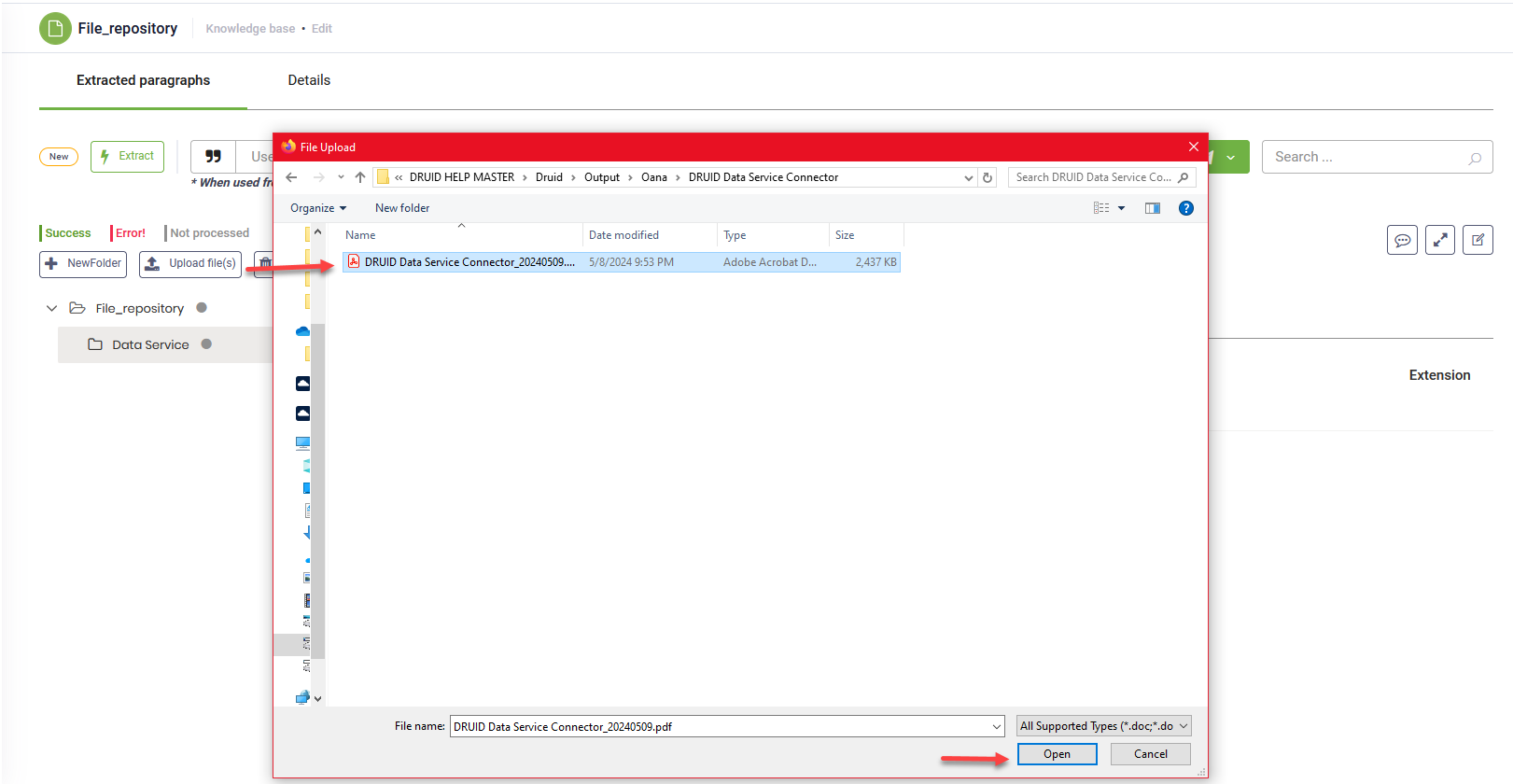
The selected file(s) appear in the tree under the selected folder.
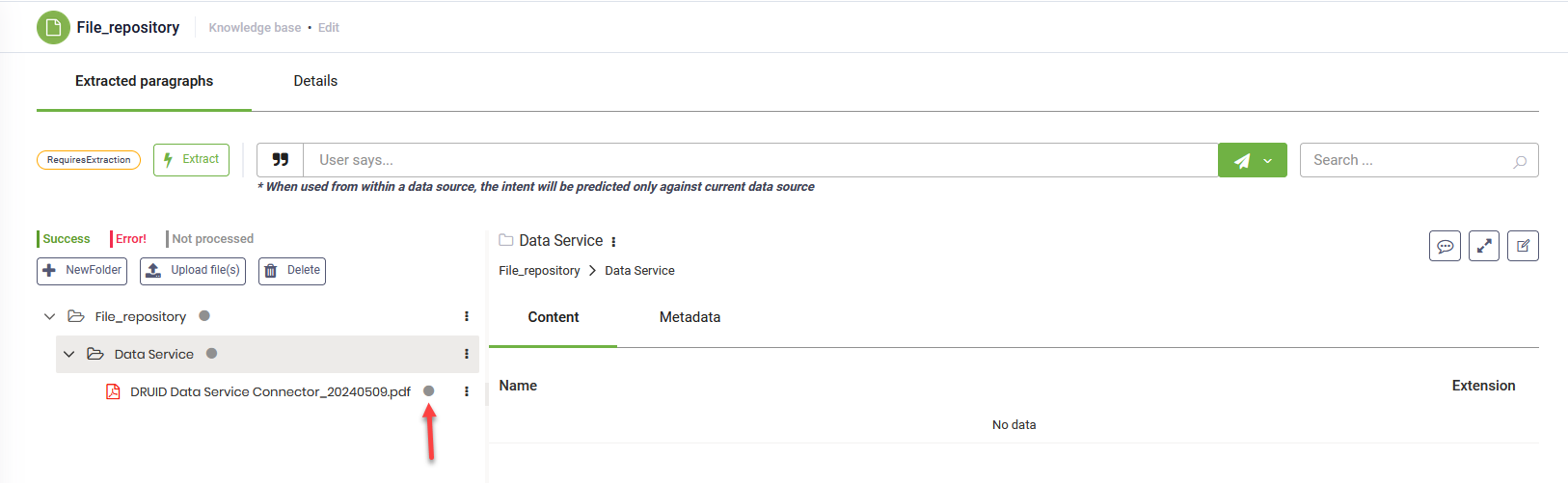
Step 3. Extract the data
You can extract paragraphs from the entire File repository (the data source root) or from specific nodes / leaves. Choose which nodes to include or exclude in the extraction.
To extract data from the root library, click the Extract button ( ) at the top left corner of the page.
) at the top left corner of the page.
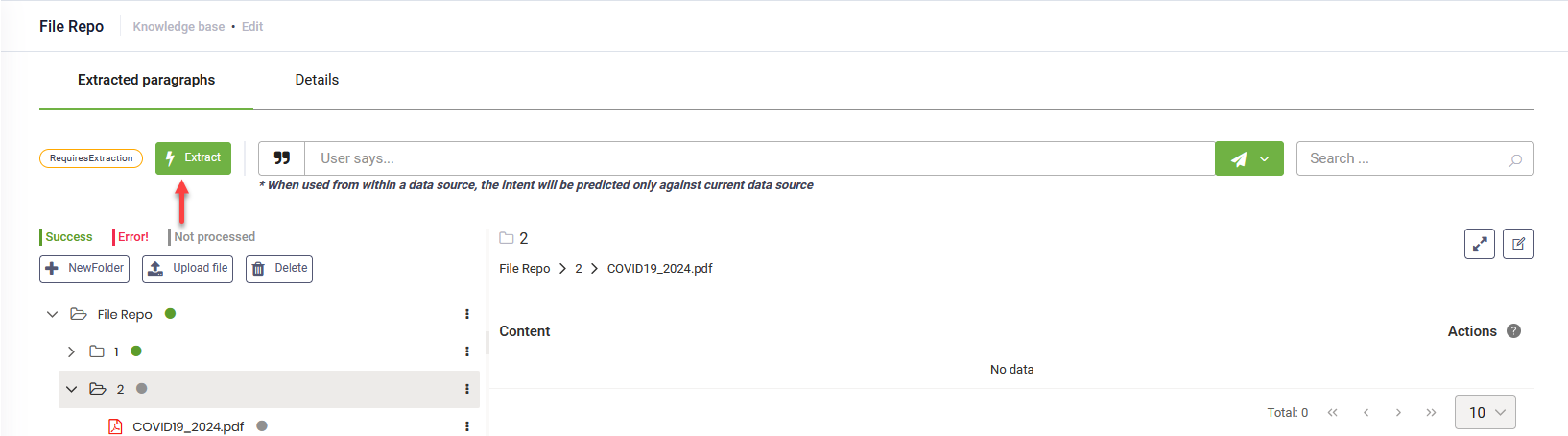
You can extract data only from specific documents by using bulk actions.
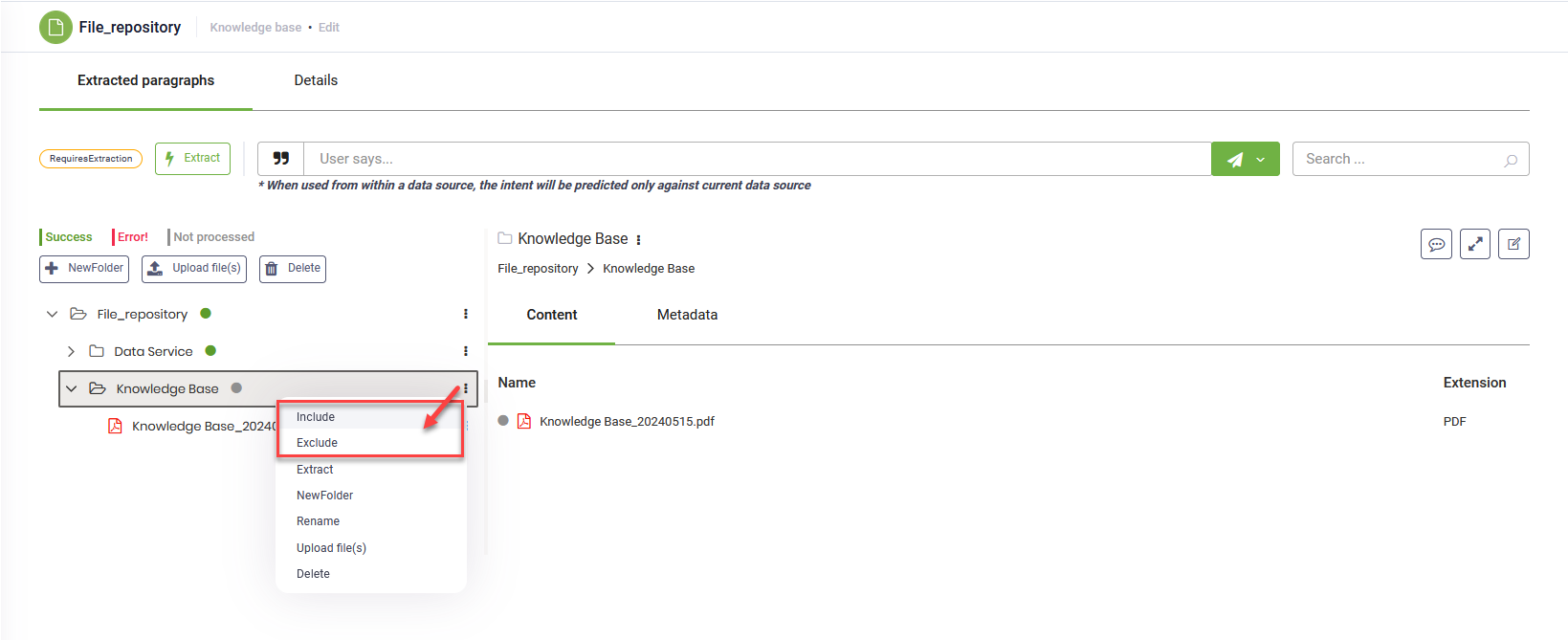
If you want to extract data from specific nodes or exclude nodes from extraction, click the dots next to each node and select Include or Exclude. If you want to exclude specific leaves within a specific node, hover over it, click the dots and select Exclude.
To extract data only from a specific node / leaf, click the dots next to the tree element and select Extract.
The green status icon next to the file or folder indicates that the articles extraction process has been completed successfully.
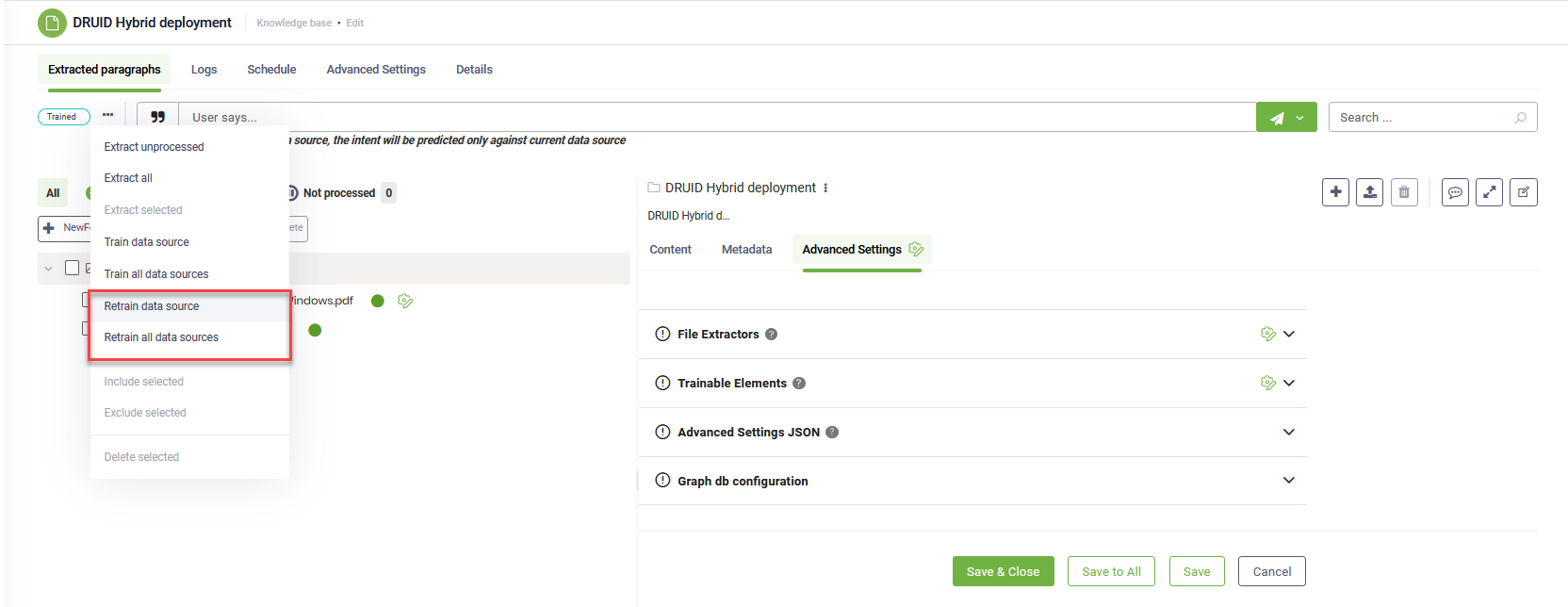
Step 4. Train the data source
To ensure the KB Engine searches through the data source paragraphs, train your data source by clicking the Train button at the top-left corner of the data source or select Train data source from the actions menu. Alternatively, you can Train all data sources.
Viewing extracted paragraphs
To view the extracted articles from a specific document, click on the desired leaf in the file repository explorer.
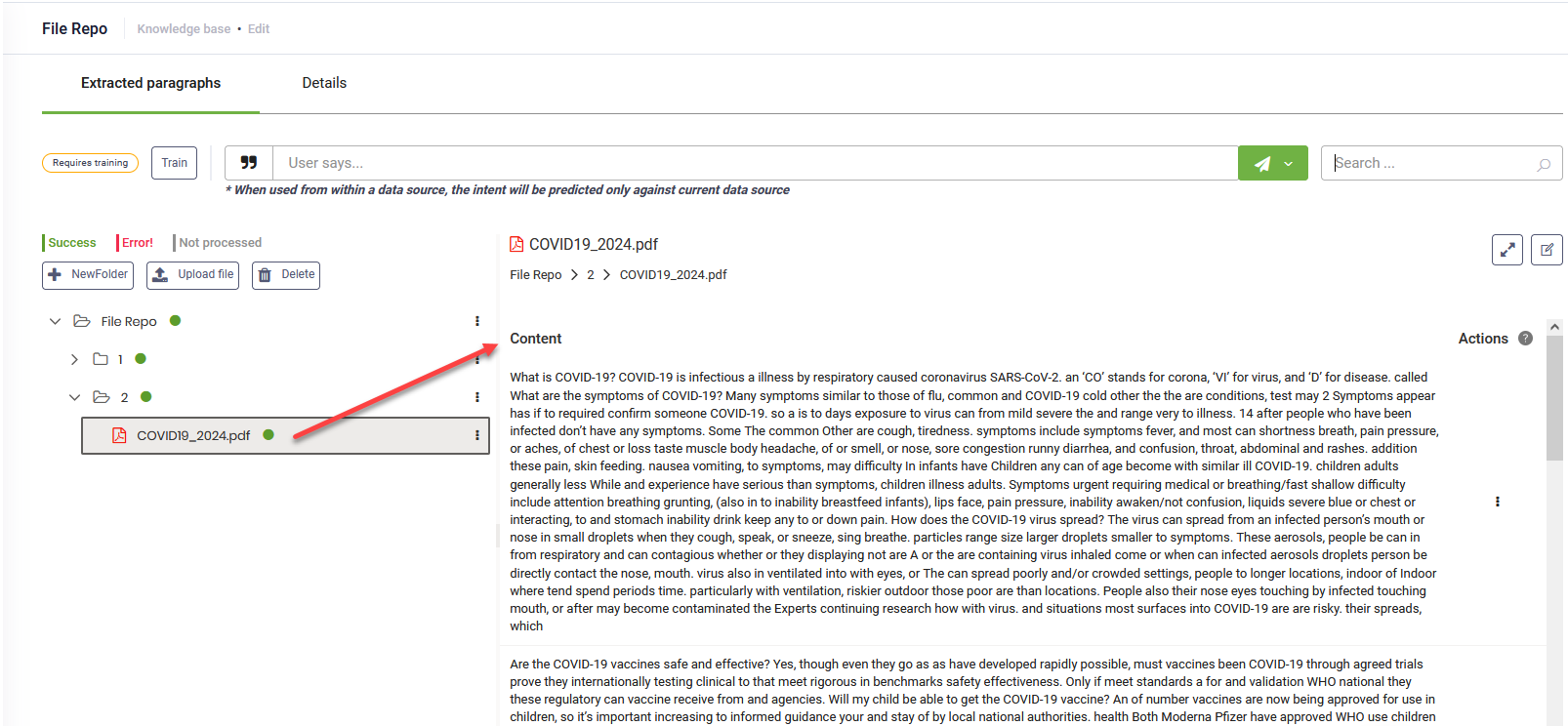
Testing the data source performance
Testing the performance of a data source is important because it ensures that the extracted paragraphs are relevant. This process helps identify and rectify any issues, improving the overall quality and effectiveness of your AI Agent responses. By validating the data source performance, you can enhance user satisfaction.
To test the performance of the data source, on the Extracted Paragraphs page, in the User Says area, enter a question and select the language. All matched paragraphs will be displayed along with their scores.
You can improve the performance of the data source by reviewing and editing the paragraphs based on your needs.
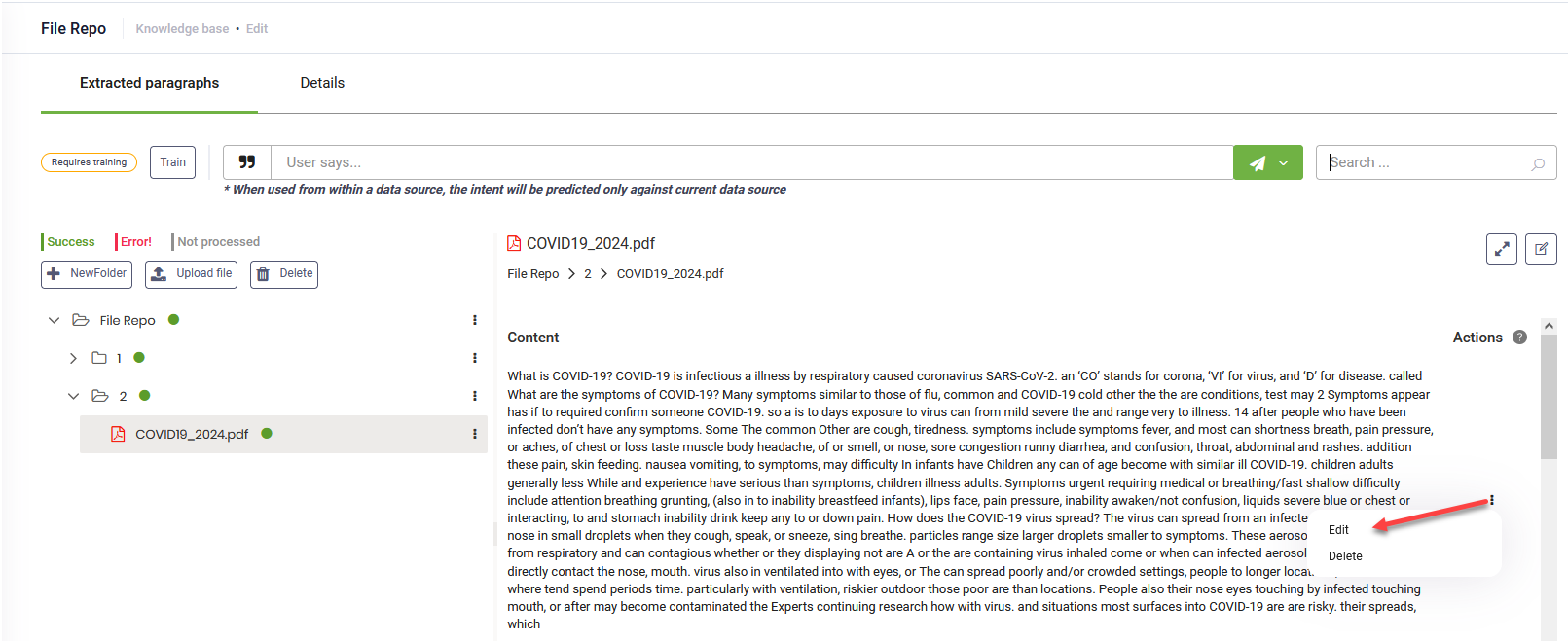
Editing paragraphs
To edit a text article, click the dots next to it and select Edit.
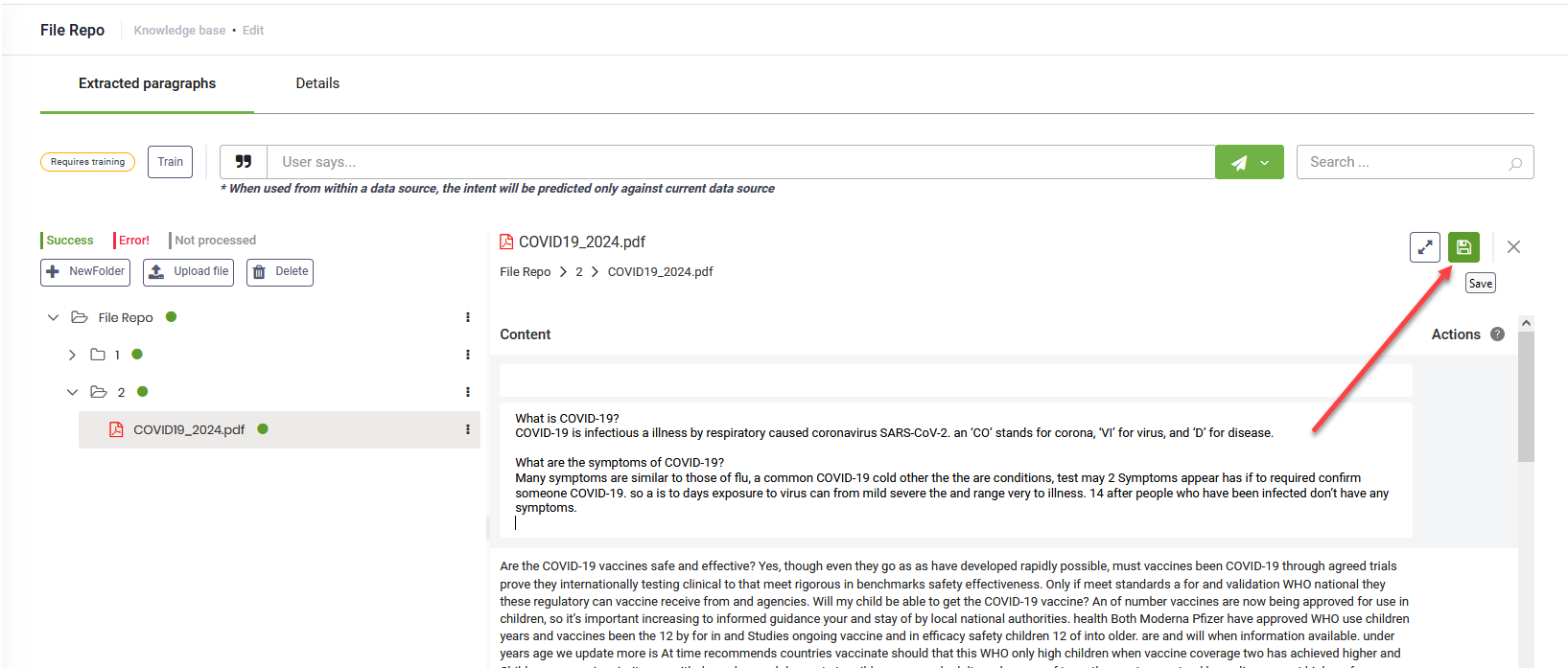
Make the desired changes and click the Save icon at the top-right corner of the page.
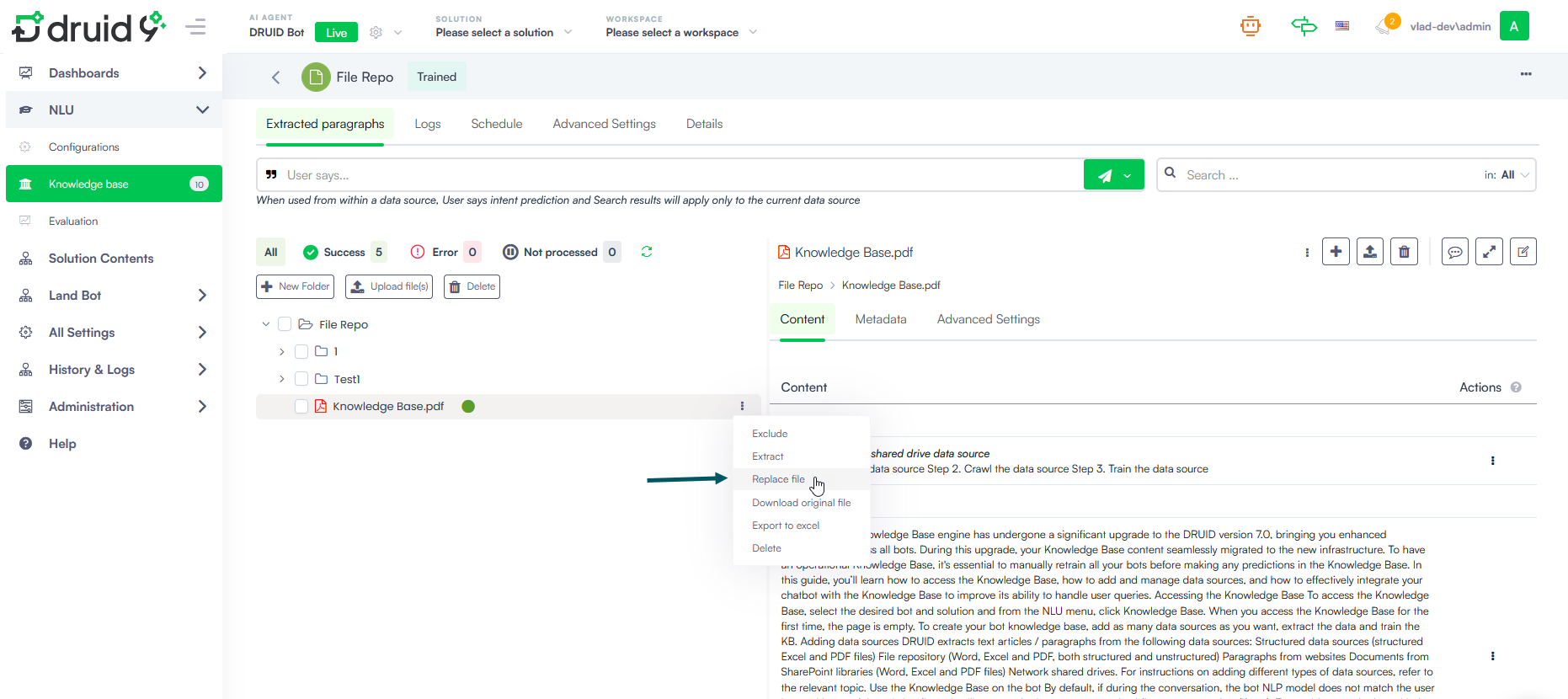
Replace files
When you replace a file, the system keeps all associated metadata (including KBWebsitePageId) and updates only the file content.
To replace a file:
- In the tree explorer, locate the file you want to update.
- Click the More options menu (three dots) next to the file.
- Select Replace file.
- Upload the new version of the file using the same file name.
The system replaces the existing file and preserves all associated metadata.
Fine-tuning Predictions
You can configure Advanced Settings at both the data source and node/leaf levels to achieve more precise predictions. This approach offers granular control, allowing you to adjust the extractors and trainable elements, resulting in better accuracy and performance. Unlike KB-level settings, which apply changes broadly, this targeted method adapts configurations to the unique needs of each data source or element, streamlining your authoring process.
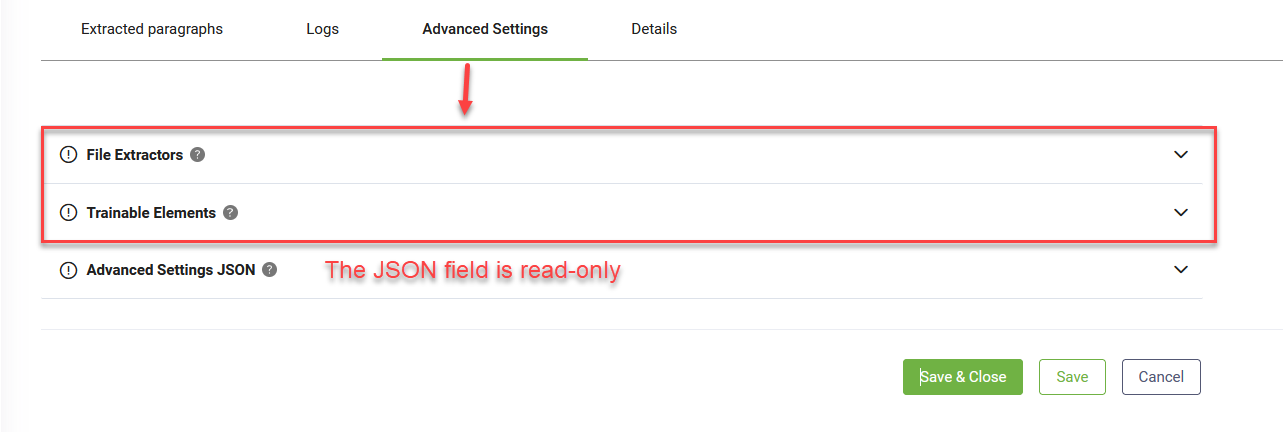
Fine-tuning at the data source level
- Navigate to the desired data source.
- Select the Advanced Settings tab.
- Modify advanced parameters as needed and save the settings.
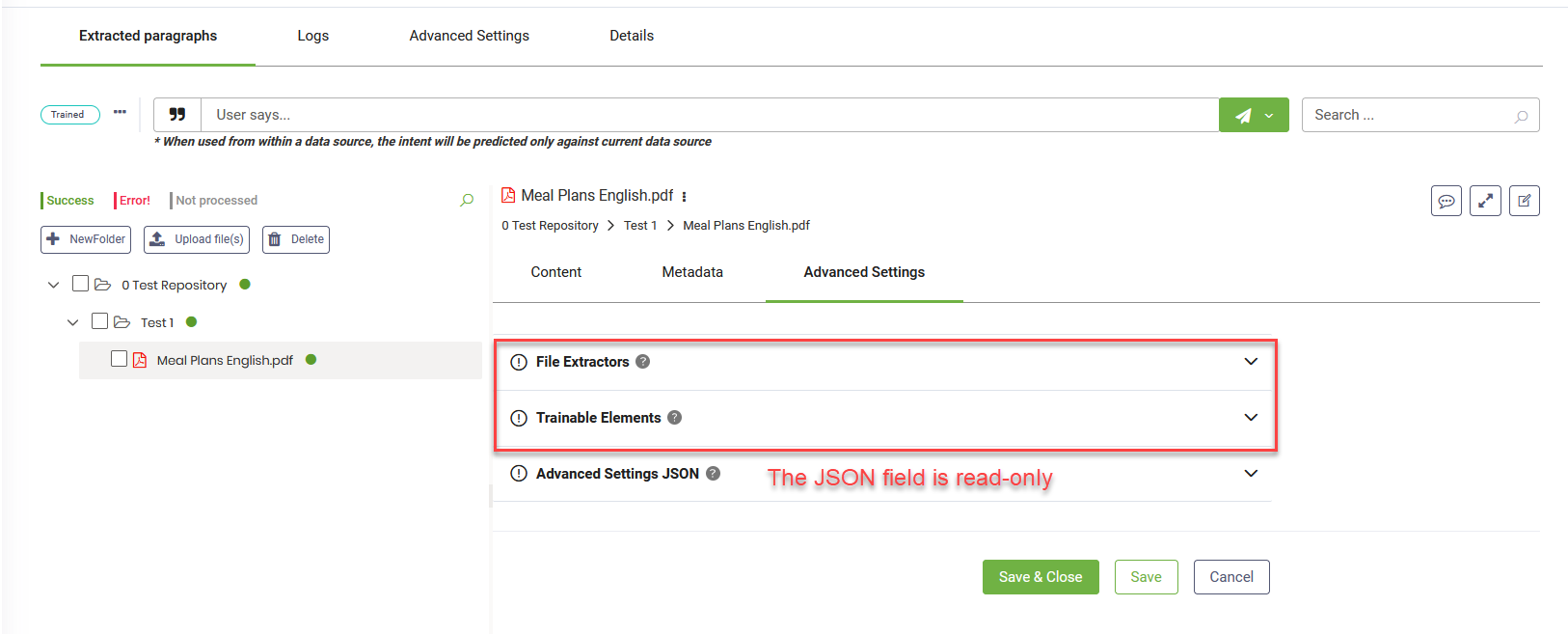
Fine-tuning at the node or leaf level
- In the tree explorer, select the desired node or leaf.
- On the right side, select the Advanced Settings tab.
- Modify advanced parameters as needed and save the settings.
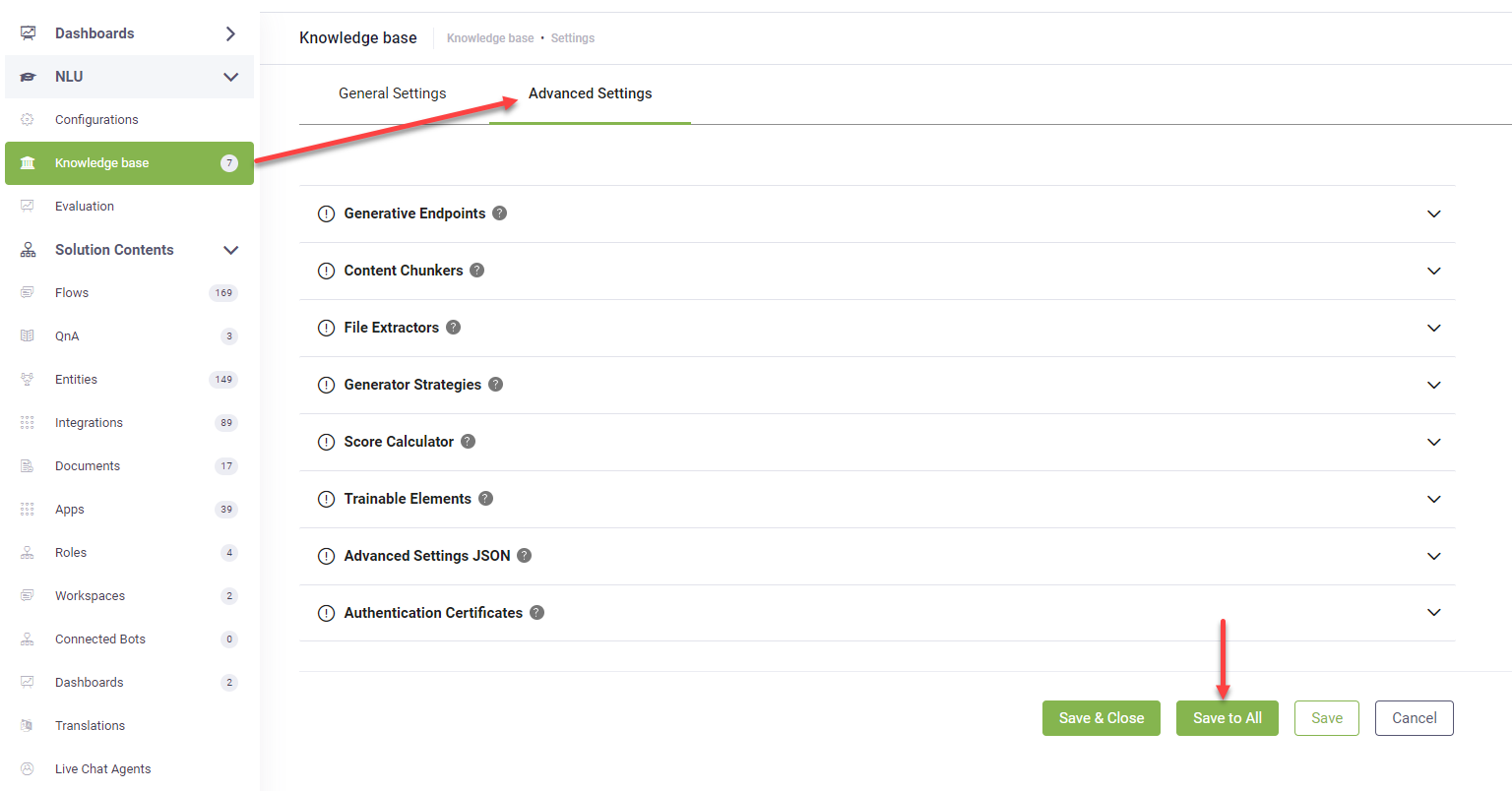
Reset advanced settings
To reset advanced configurations at the data source and node/leaf levels to match the KB Advanced settings, go to Knowledge Base > Advanced Settings and click the Save to All button. This action streamlines your settings management by applying consistent KB Advanced settings across your entire configuration with just one click.
Enhance KB prediction
Refine your articles by transforming unstructured data into a question-and-answer format. Edit articles and add question / title / short description.
Access the Knowledge Base Advanced Settings, set the "trainableColumns" parameter to "Question,Answer", then train the Knowledge Base. The KB Engine will leverage both questions and answers from unstructured data sources during the prediction process, ultimately leading to improved prediction accuracy.
Editing and deleting file repository elements
You can edit file repository nodes and leaves by adding new elements, renaming, or deleting existing ones. Hover the mouse over the desired element in the tree explorer, click the dots and select the desired action.
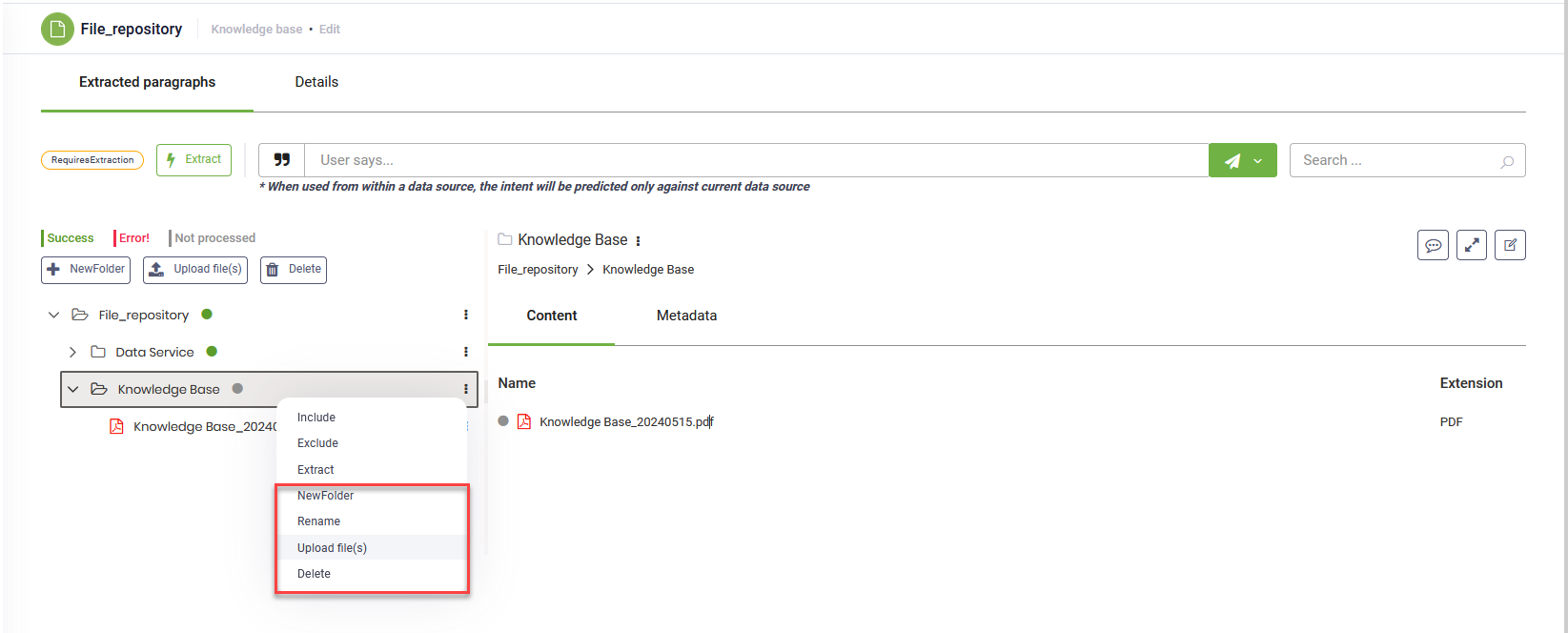
You can also delete tree elements by clicking on the desired tree element in the file repository explorer and then clicking the Delete button at the top left corner of the page under the data source status.
After making updates to your file repository, it's crucial to retrain your data source. This ensures the KB Engine recognizes these updates and provides accurate responses to user queries. Click the Train button at the top-left corner of the data source.