File Extractors
File Extractors are Druid-specific tools that help the Knowledge Base (KB) engine extract content from various file formats. By default, the Standard Extractor is applied to all file MIME types, with the Basic Content Chunker enabled. You can switch the content chunker to an LLM Chunker for any file MIME type as needed.
This section provides an overview of the available file extractors for different MIME types, allowing you to select the most suitable option based on your data format.
You can configure file extractors at multiple levels:
- Global level (applies to all files and data sources within the KB)
- Unstructured data source devel (specific to a data source)
- Node and leaf level (granular customization within a data source tree).
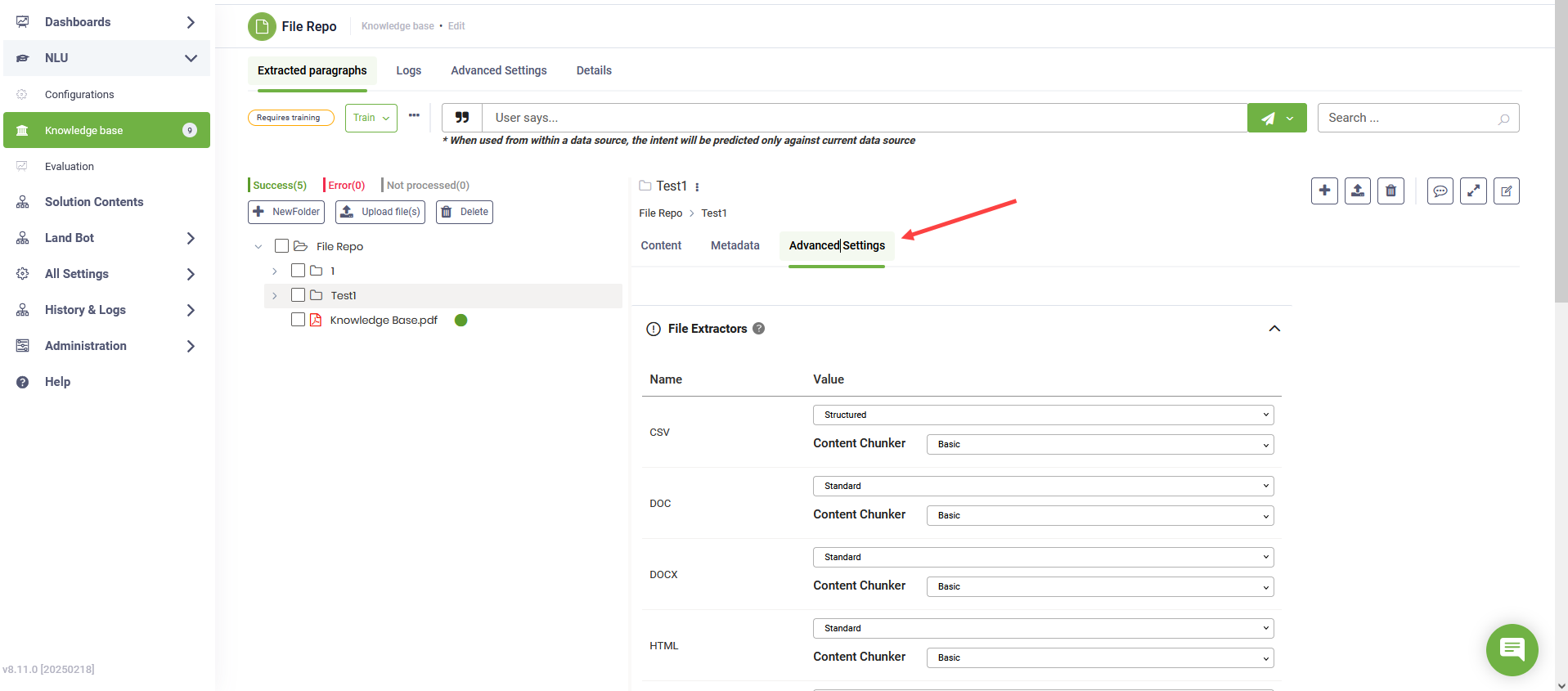
Once you've selected the preferred file extractor(s), click Save to apply your changes.
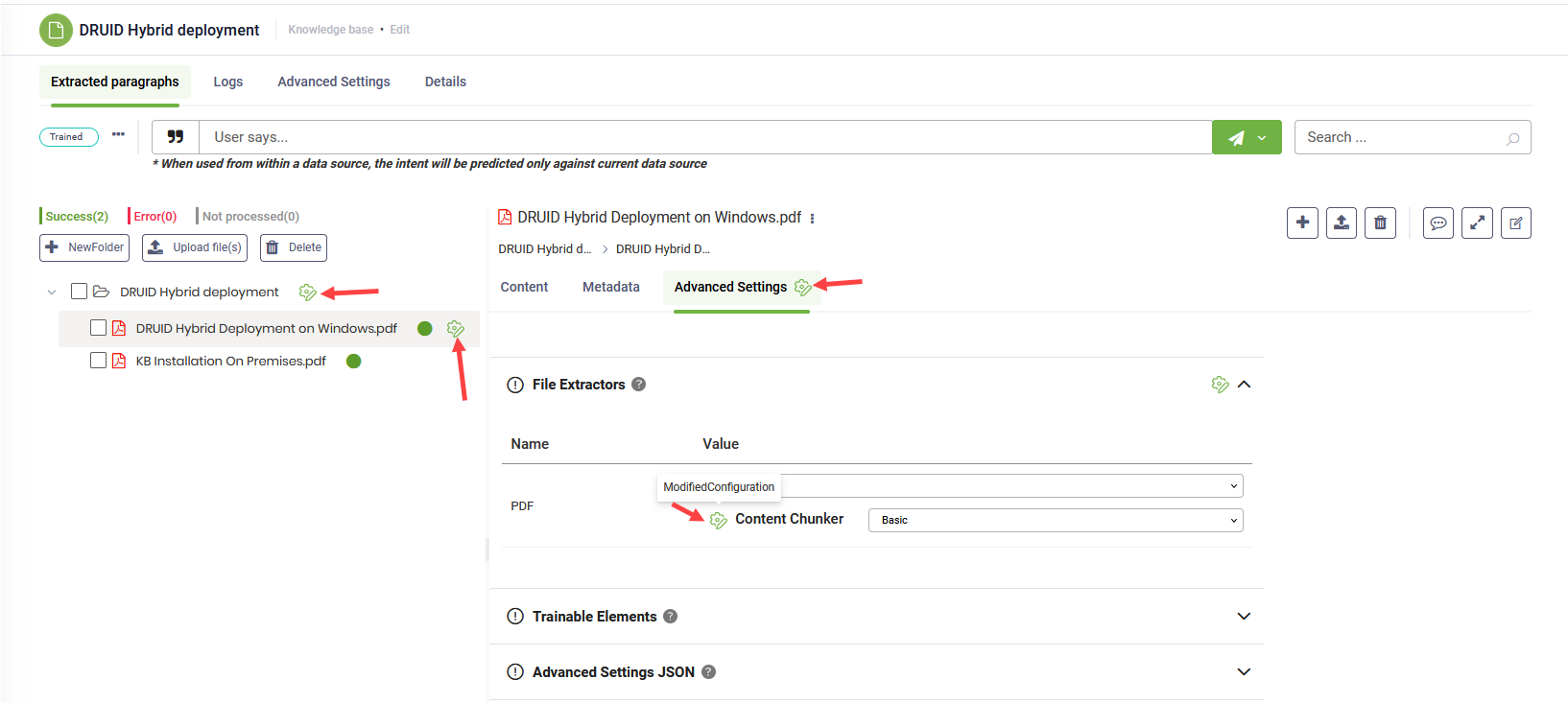
The Modified Configuration icon indicates updates to advanced settings at both the data source level and tree elements. In the Advanced Settings tab, the icon also appears next to modified parameters, allowing authors to easily identify what has changed.
CSV Extractors
| File Extractor | Description | When to use |
|---|---|---|
| Pan | The Pan Extractor is designed for handling complex, mixed, or loosely formatted CSV files. It is best suited for situations where the structure of the CSV is not strictly uniform, making it ideal for handling variations or irregularities in the data. | You need to extract data from CSV files with unstructured or inconsistent formats. |
| Structured | The Structured Extractor is optimized for clean, well-formed CSV files where each row follows a consistent format. It is faster and more efficient for extracting data when the file adheres to a regular, predefined structure. | You have well-organized and consistent CSV files with a fixed structure |
DOC and DOCX Extractors
For DOC and DOCX file MIME types, Druid supports only the Standard Extractor. This extractor processes text content while preserving the document’s basic structure, including headings, paragraphs, and lists. It ensures accurate text extraction for knowledge base indexing and search.
Image Extraction
Image extraction is enabled by default. Images are stored in Druid storage and linked with a 30-minute authentication token. The image link is embedded in the extracted article paragraph, allowing temporary access within the chat.
OCR for Pictures
You can enable Use OCR for pictures in the extractor settings. When set to True, the extractor performs OCR on images found in the file instead of saving the image to the Druid storage. This makes the text within images searchable in the Knowledge Base.
HTML Extractors
For HTML file types, Druid supports the Standard extractor. It extracts text content while preserving basic structure, such as headings, paragraphs, lists, and links, and removing unnecessary web formatting.
Image Extraction
Image extraction is enabled by default. Images are stored in Druid storage and linked with a 30-minute authentication token. The image link is embedded in the extracted article paragraph, allowing temporary access within the chat.
OCR for Pictures
You can enable Use OCR for pictures in the extractor settings. When set to True, the extractor performs OCR on images found in the HTML code rather than providing an access link to the image file in the KB Article.
PDF Extractors
Druid supports the following extractors for PDF file MIME types: Elpis, Omni, Standard, and Structured. Each extractor is designed for different types of PDF documents, ensuring optimal content extraction based on document structure and format.
| File Extractor | Description | When to use | OCR & Image Capabilities |
|---|---|---|---|
| Daguerre | Designed for high-accuracy extraction of complex documents. It can extract both text and images |
Druid version 9.19+ supports OCR for pictures. |
|
| Elpis |
Optimized for multimedia-rich PDFs. It can extract both text and images, making it ideal for documents that include diagrams, charts, and embedded visuals. |
If your PDFs contain important images that should be accessible in extracted content. |
Druid version 9.19+ supports OCR for pictures. Druid version 9.20+ supports the Auto mode when performing OCR for pictures. |
| Omni | The Omni Extractor is specifically designed to extract content from structured PDFs. | For structured PDFs added to unstructured data sources to improve article quality. | Does not support OCR for pictures. |
| Standard | The Standard Extractor is a general-purpose tool that extracts text content only, without preserving document structure or layout. It works well for simple PDFs without complex formatting. | When you need basic text extraction without concerns about layout or formatting. | Does not support OCR for pictures. |
| Structured | The Structured Extractor is optimized for PDFs with consistent formatting, ensuring accurate extraction of headings, tables, and paragraphs. | Extract text from highly structured PDFs with a defined layout. | Does not support OCR for pictures. |
Image Extraction and OCR modes
For the Elpis and Daguerre extractors, you can configure Use OCR for pictures using one of three modes:
- False (Default): It extracts the image, stores it in Druid storage, and embeds a link with a 30-minute authentication token in the paragraph, allowing users to view the original image within the chat.
- True: The extractor performs OCR on all images to convert them into searchable text; the original images are not stored.
- Auto: A hybrid intelligence mode. If the extractor finds both images and text on the same page, it skips OCR for the image. Instead, it extracts the image, stores it in Druid storage, and embeds a link with a 30-minute authentication token in the paragraph, allowing users to view the original image within the chat.
OCR for Pictures
You can enable Use OCR for pictures in the extractor settings. When set to True, the extractor performs OCR on images found in the HTML code rather than providing an access link to the image file in the KB Article.
XLS, XLSM, and XLSX Extractors
Druid provides multiple extractors for XLS, XLSM, and XLSX file types, each designed for different extraction needs. Choose the appropriate extractor based on your need for table structure, formatting, or bulk data extraction.
| File Extractor | Description | When to use |
|---|---|---|
| Pan | Extracts content from Excel files while preserving table structures. | Use when maintaining the original table layout is important. |
| OpenPan |
Efficiently extracts content from .xlsx and .xlsm files, significantly reducing processing time, especially for large spreadsheets. NOTE: This file extractor is available in DRUID 8.15 and higher.
|
Recommended for general .xlsx and .xlsm file extraction, particularly when dealing with large files where speed and efficiency are crucial. |
| Structured | Extracts structured data by identifying patterns within rows and columns, ensuring a clean and organized output. | Ideal for extracting well-structured tables for better indexing and search accuracy. |
| Standard | Extracts text-based content while ignoring complex formatting or embedded objects. | Suitable for general text extraction without requiring table structure preservation. |
| Reader | Processes the entire spreadsheet and extracts data efficiently, including multiple sheets if applicable. | Best for bulk extraction where data needs to be read from multiple sheets. |
PPTX and PPSX Extractors
For PPTX and PPSX file MIME types, DRUID supports only the Standard extractor for content processing.
JSON Extractors
For JSON file MIME types, DRUID supports only the Structured extractor for content processing.
To add content from third-party systems (e.g., Salesforce, Confluence) to the Knowledge Base, you can use structured JSON files. This extraction method is available for Unstructured, File Repository, and Custom data sources starting from DRUID 8.9.
For Custom data sources, third-party tools must support REST APIs for data exchange. Extracted content — whether in Word documents, Excel files, PDFs, or JSON format — must be mapped into a structured JSON file before integration.
JSON File Structure
The JSON file should follow this format:
JSON structure
[
{
"Title": "Sample Title",
"Content": "Content 1"
},
{
"Title": "Sample Title 2",
"Content": "Content 2",
"PageNumber": "3"
},
{
"Title": "Sample Title 3",
"Content": "Sample Content 3",
"SheetName": "Sheet1"
}
]The following table provides the description of each JSON property:
| Property | Required | Description |
|---|---|---|
| Title | Yes | The title of the content entry. |
| Content | Yes | The content to be added to the Knowledge Base. |
| PageNumber | No | Relevant only when mapping data from PDF documents. Specifies the page number from where the content was extracted. |
| SheetName | No | Relevant only when mapping data from Excel files. Specifies the sheet name where the content was extracted. |
MP4 Extractors
For MP4 file MIME types, DRUID supports DRUID Basic and LLM extractors.